
해시 테이블 (Hash Table)
‘키에 대한 해시 값을 사용하여 값을 저장하고 조회하며, 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 associate array’
배열 구조로 되어있는 자료 구조이다.
키(key)와 데이터(value)을 짝지어서 저장한다 (키 — 데이터).
이를 통해 찾고자 하는 데이터에 용이하게 접근할 수 있도록 한다.
키: 데이터를 찾을 때 사용하기 위한 (데이터의 인덱싱을 위한) 값으로, 유일하게 존재하며 중복이 불가하다.
데이터: 키를 이용하여 찾을 수 있는 값을 말한다.

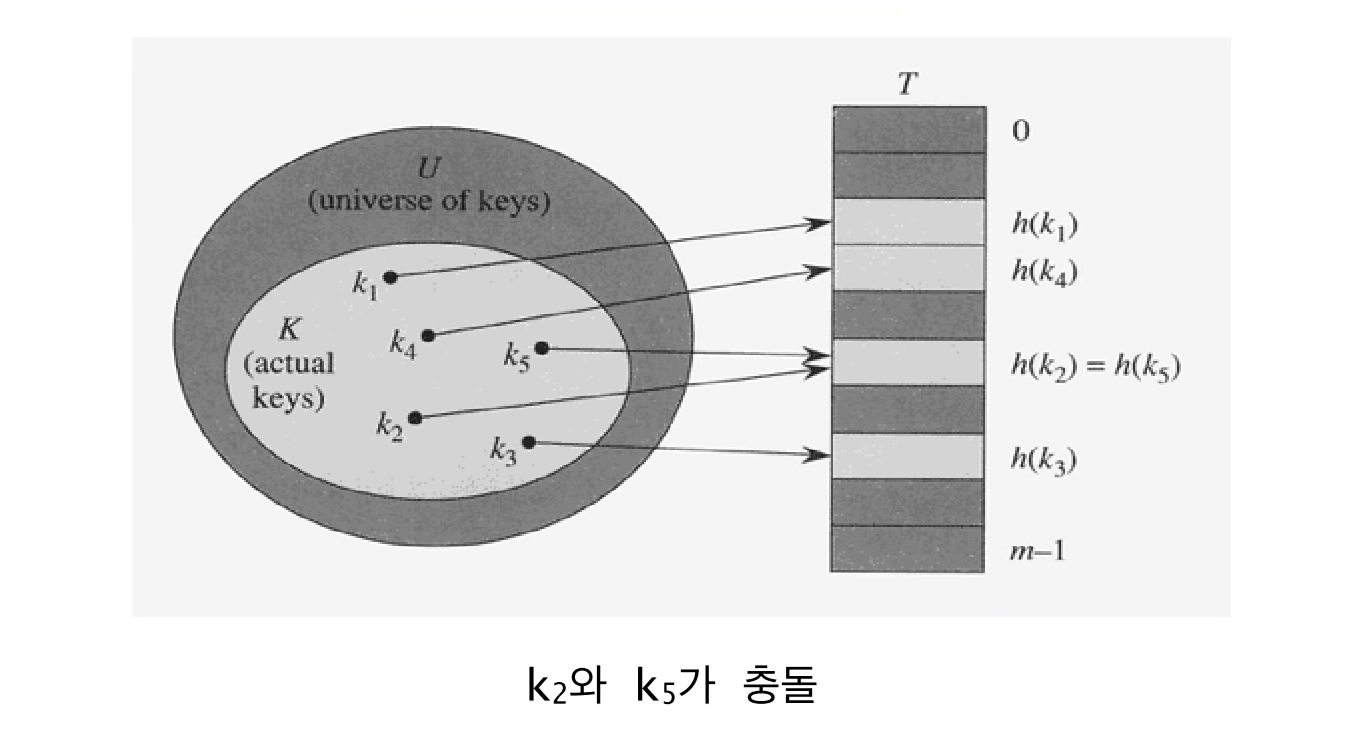
실제로 키 값에 해시 함수(hash function)를 적용시켜 데이터를 저장하는 위치가 결정된다.
해시 함수를 만들 때에는 유의할 점이 몇 가지가 있다.
해시 테이블을 이용한 데이터 접근의 시간 복잡도
해시 충돌 (Hash Collision)
만일 혹시라도 해시 함수가 결과값으로 같은 저장 위치를 제공하면, 충돌이 발생한 것이다 (Hash Collision). 충돌을 해결하기 위해서는 세 가지의 방법이 있다.
체이닝(Chaining) - 가장 일반적인 방법
하나의 저장 위치에 생성된 노드의 개수에 따라 (JDK1.8에서는 8개 기준) 연결 리스트(Linked List) 또는 트리(Trie)를 이용하여 데이터들을 묶음으로 연결해준다. 같은 위치에 두 개 이상의 데이터들이 각각 다음 데이터를 가리키는 방식으로 연결되는 것이다. 선형 탐색으로 데이터를 찾게 되기 때문에 구현 시 시간 복잡도가 O(N)으로 늘어난다. 만약 데이터가 삭제 되었는데, 묶음의 일부였으면 그 부분에 더미 노드(형태만 갖춘 객체)를 추가해서 이전과 이후 객체들의 탐색에 영향이 없도록 한다.코드 예시 (출처: Programiz)
오픈 어드레싱 (Open Addressing)
하나의 저장 위치에는 하나의 데이터만 저장하도록 한다. 이를 위해 세 가지의 방식을 사용한다. Linear probing (선형 조사)•
저장 위치에 이미 데이터가 있으면 새로운 해시 함수를 사용해 다음 저장 위치 (숫자 상으로 표현할 때 1씩 증가)를 확인한다. 순서대로 저장 위치를 찾는 것이라 시간이 많이 걸린다 (군집화).
Quadratic probing (이차 조사) •
저장 위치에 이미 데이터가 있으면 새로운 함수를 사용해 다음 저장 위치 (고정 아님, 숫자 상으로 표현할 때 현재 반복 횟수의 제곱, 예: 2번째 반복이면 4, 만큼을 더한 위치)를 확인한다.
Double Hashing (이중 해시)•
현재 해시 함수 외 제 2의 해시 함수를 사용한다. 위 두 방법과 다르게 군집화 (clustering)을 방지할 수 있다. (똑같이 반복문을 활용해) 2번째 해시 함수가 다음 저장 위치를 얼마나 떨어진 곳으로 할지 결정한다 (반복 횟수 * 해시 함수 값을 더하여).
해시 테이블의 크기는 일정한데 객체의 개수가 계속해서 증가하면 계속해서 충돌이 발생해 궁극적으로 구현 시간이 길어지므로 재해싱 (Rehashing)을 적용해야 한다.
해시 함수 (Hash Function)
해시 함수를 주어진 문자열로 된 키에 적용할 때에는 함수가 생성하는 값의 범위가 넓어야 하며, 하나의 문자에 해시 코드가 좌지우지 되어서는 안된다.
간단한 해시 함수
h(k) = k % m즉, key를 하나의 자연수로 해석한 후 테이블의 크기 m으로 나눈 나머지를 데이터가 저장될 주소로 사용한다. 항상 0 ~ m-1 사이의 정수가 된다. <출처: https://ict-nroo.tistory.com/76>롤링 해시 (rolling hash)
O(1)의 시간 복잡도를 갖는 해시 함수로 롤링 해시가 있다. 문자열의 맨 앞의 문자를 떼어내서 맨 뒤에 붙이는 방식으로 해시 코드를 만들어내는 함수이다.Java에서의 해시
자바에서는 이미 HashTable과 HashMap이라는 클래스가 구현되어 있다.
(파이썬에서는 Dictionary를 이용해 해시 테이블을 구현할 수 있다.)
HashTable vs HashMap
둘의 차이는 보조 해시 함수의 유무로 결정된다. HashMap이 지속적으로 성능 개선이 되고 있는 반면에 HashTable은 초창기 자바의 실행 환경에 대한 하위 호환성을 제공하는 데에 가치를 둔다. HashMap은 remove()를 빈번하게 사용하기 때문에 Open Addressing보다는 Chaining을 사용한다.백엔드에서의 해시
“웹 애플리케이션 서버의 경우에는 HTTPRequest가 생성될 때마다, 여러 개의 HashMap이 생성된다. 수많은 HashMap 객체가 1초도 안 되는 시간에 생성되고 또 GC(garbage collection) 대상이 된다. 컴퓨터 메모리 크기가 보편적으로 증가하게 됨에 따라, 메모리 중심적인 애플리케이션 제작도 늘었다. 따라서 갈수록 HashMap에 더 많은 데이터를 저장하고 있다고 할 수 있다.”
백엔드 개발자로서 해시 함수를 오버라이드하여 변경하여 사용하는 등 해시를 활용하여 컴퓨터 메모리를 관리하여야 하므로, 해시에 대한 기본적인 이해는 필요하다.