
.png&blockId=18f00b21-a9bc-4e35-aeb8-ecb07bddb89a)
Lock Striping
자료구조 관점에서 한 자료구조 전체가 아닌 일부분(buckets or stripes 단위)에 락을 적용하는 것
•
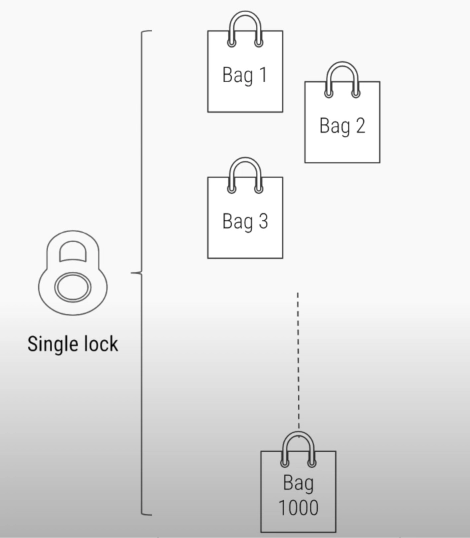
스레드가 잠금을 획득한 다음 bag에 접근할 수 있다.
단점 : 스레드 하나가 끝날때 까지 기다려야한다.
•
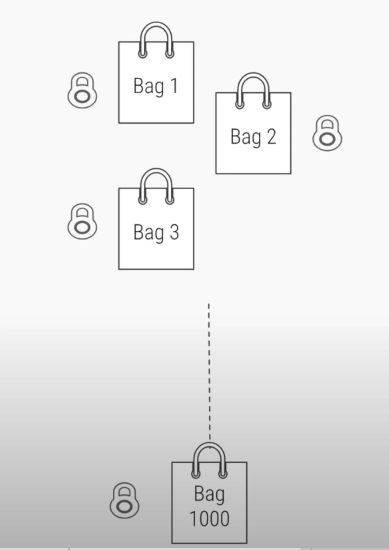
여러 스레드가 동시에 서로 다른 bag에 접근 할 수있다.
단점 : 여러개의 bag이 있으면 여러개의 잠금 장치가 필요하고 메모리 소모가 심하다.
Lock Striping이란?
독립적인 객체를 여러 가지 크기의 단위로 묶어내고, 묶인 블록 단위로 락을 나누는 방법
•
그룹에 하나의 잠금장치가 있는 개념
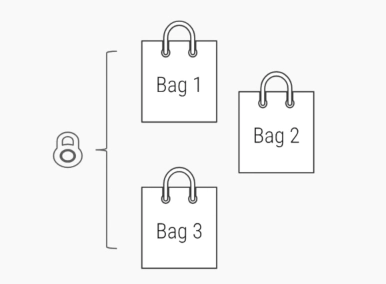
대표적인 예 : ConcurrentHashMap
•
key와 value에 null을 허용하지 않는다.
•
동기화를 보장한다.
•
멀티 스레드 환경에서 사용
◦
HashMap은 싱글스레드에서 사용
•
HashMap의 동기화 문제를 보완하기 위해 만들어짐 (HashMap을 thread-safe 하도록 만든 클래스)
default 생성자
table size가 16으로 이루어져 있다.
= bucket의 수가 16이고 16개의 thread가 동시 쓰기를 할 수 있다.
/**
* Creates a new, empty map with the default initial table size (16).
*/
public ConcurrentHashMap() {
}
Java
복사
예제
•
10개의 스레드에서 각각 1000번을 반복하며 랜덤한 값을 입력할 때 엔트리의 사이즈를 비교하는 코드
import java.util.Collections;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class MultiThreadsTest {
private static final int MAX_THREADS = 10;
private static Hashtable<String, Integer> ht = new Hashtable<>();
private static HashMap<String, Integer> hm = new HashMap<>();
private static HashMap<String, Integer> hmSyn = new HashMap<>();
private static Map<String, Integer> hmSyn2 = Collections.synchronizedMap(new HashMap<String, Integer>());
private static ConcurrentHashMap<String, Integer> chm = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(MAX_THREADS);
for( int j = 0 ; j < MAX_THREADS; j++ ){
es.execute(new Runnable() {
@Override
public void run() {
for( int i = 0; i < 1000; i++ ){
String key = String.valueOf(i);
ht.put(key, i);
hm.put(key, i);
chm.put(key, i);
hmSyn2.put(key, i);
synchronized (hmSyn) {
hmSyn.put(key, i);
}
}
}
});
}
es.shutdown();
try {
es.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Hashtable size is "+ ht.size());
System.out.println("HashMap size is "+ hm.size());
System.out.println("ConcurrentHashMap size is "+ chm.size());
System.out.println("HashMap(synchronized) size is "+ hmSyn.size());
System.out.println("synchronizedMap size is "+ hmSyn2.size());
/*
for( String s : hm.keySet() ){
System.out.println("["+s+"] " + hm.get(s));
}
*/
}
}
Java
복사
Hashtable size is 1000
HashMap size is 1281
ConcurrentHashMap size is 1000
HashMap(synchronized) size is 1000
synchronizedMap size is 1000
Java
복사
 Hashtable은 메소드(get(), put(), remove() 등)에 synchronized 키워드가 붙어 있다. 하지만 스레드간 동기화 락은 매우 느린 동작이라는 단점이 있다. HashMap을 쓰더라도 synchronized 블록을 선언해 주면 정상으로 동작을 한다.
Hashtable은 메소드(get(), put(), remove() 등)에 synchronized 키워드가 붙어 있다. 하지만 스레드간 동기화 락은 매우 느린 동작이라는 단점이 있다. HashMap을 쓰더라도 synchronized 블록을 선언해 주면 정상으로 동작을 한다.