

Redis는 Remote Dictionary Server의 약자로, Memory 상에서 Key - Value 의 형식으로 데이터를 저장하는 Database의 일종입니다. 여태까지 사용해온 MySQL과 같은 관계형 데이터베이스와는 다르게, 문자열, 리스트와 같은 자료형을 지원합니다. 실제 사용은 Java의 Map 인터페이스, Python의 Dictionary와 유사하게 사용할 수 있습니다. Spring Boot에서는 주로 RabbitMQ와 함께 비동기 통신에 사용되거나, 공유되는 캐시로서 활용됩니다.
Redis역시 Docker로 간편하게 설치할 수 있습니다.
docker run --name redis-stub -d -p 6379:6379 redis:6-alpine
Bash
복사
마찬가지로 Docker 없이 redis를 사용하기 위해선 Redis 홈페이지의 가이드를 따라야 합니다.


Redis (NoSQL)
NoSQL이라는 용어는 현재 데이터베이스의 절대다수를 차지하는 관계형데이터베이스가, SQL을 사용해서 데이터를 다루는데 반하는 의미를 가진, SQL을 사용하지 않는 방식을 통틀어 이야기 합니다. 정확하게 한가지 형식에 국한된 데이터베이스가 아니라, 다양한 방식으로 데이터를 관리합니다.
Redis 역시 대표적인 NoSQL 데이터베이스 입니다. 위에서 언급하였듯, Java의 Map이나 Python의 Dictionary 처럼 사용할 수 있습니다. 관계형 데이터베이스와는 달리 문자열로 된 Key를 전달하면, 거기에 할당된 데이터를 반환하는 형식의 데이터베이스 입니다. Redis의 다른 특징중 하나는 In-Memory 데이터베이스 입니다. H2 데이터베이스가 그러하듯 In-Memory에서 데이터를 저장하기 때문에, 종료시에 데이터가 저장되지 않습니다.
Redis Use-Case
이런 특징으로 인해 Redis는 데이터를 저장하는 용도보단, 임시로 저장하여 공유하는 용도로 많이 사용됩니다.
어플리케이션 공유 캐시
HTTP 요청은 기본적으로 상태를 저장하지 않습니다. 사용자는 자신이 누구인지를 매 요청마다 증명해야 함을 앞서 언급하였습니다. 그리고 이 증명을 위한 데이터로 브라우저 쿠키에 토큰 데이터를 저장하고, 해당 토큰을 Backend에서 비교하여 사용자의 정보를 조회하게 됩니다.
이때 어플리케이션 내부 로직에서 사용자 정보를 저장한다고 생각을 했을 때, 하나의 어플리케이션 프로세스만 있을때는 문제가 없으나, Throughput 등의 성능 문제로 여러 프로세스를 실행하는 경우,
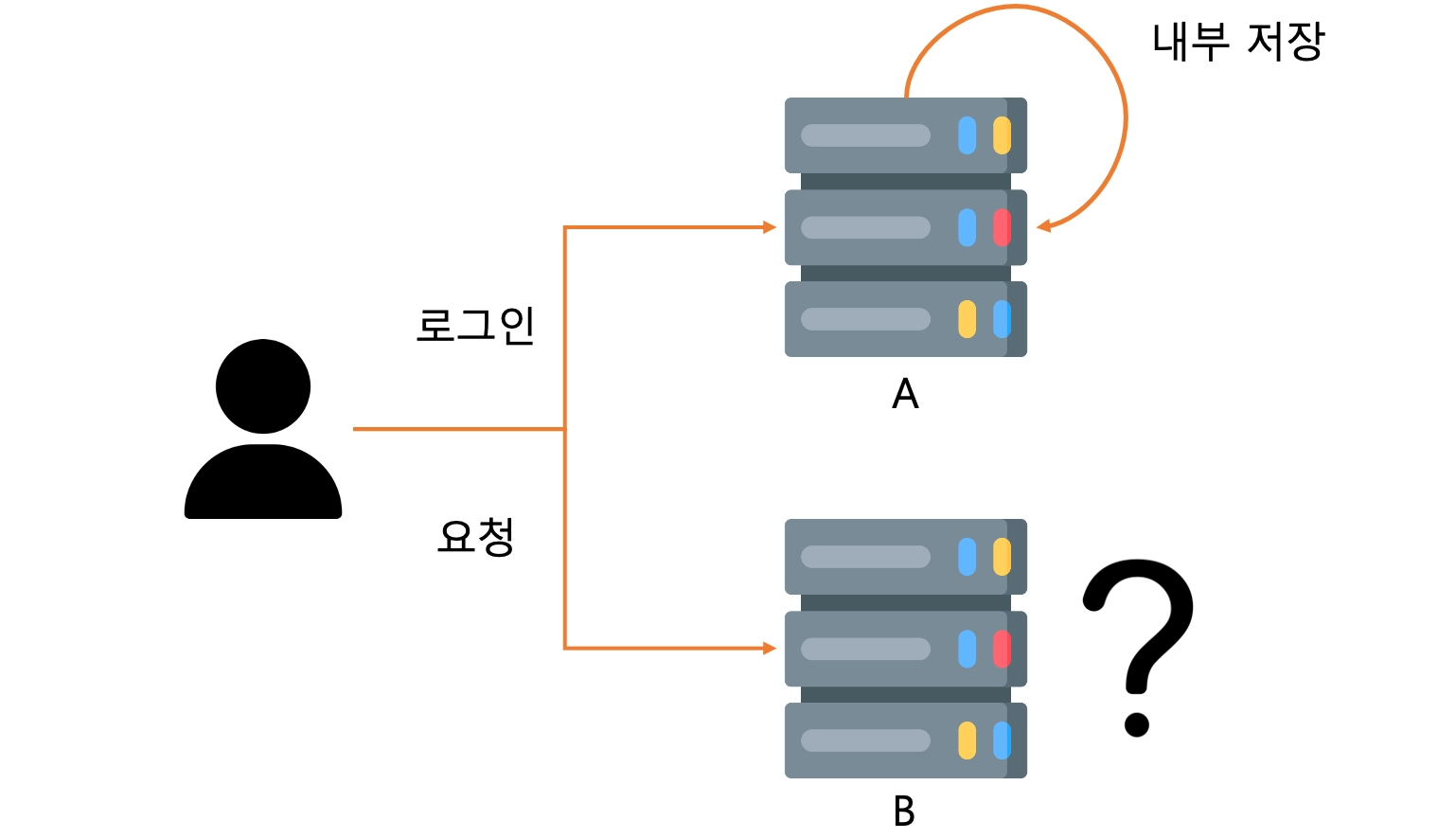
최초의 로그인이 A 에서 진행될 경우 사용자의 다음 요청이 B로 전송이 될때 사용자가 로그인 했는지 안했는지를 판단할 수 없게 됩니다. 이는 Chapter 8의 프로젝트에서도 확인할 수 있는데, 실행후 로그인 한 다음 어플리케이션을 다시 실행하게 될 경우 다시 로그인해야 한다는 점에서 알 수 있습니다.
이런 경우 어플리케이션과 별개로 접근할 수 있는 Redis에 사용자에 대한 정보를 일부를 저장함으로서 두 프로세스가 정보를 공유하도록 할 수 있습니다.
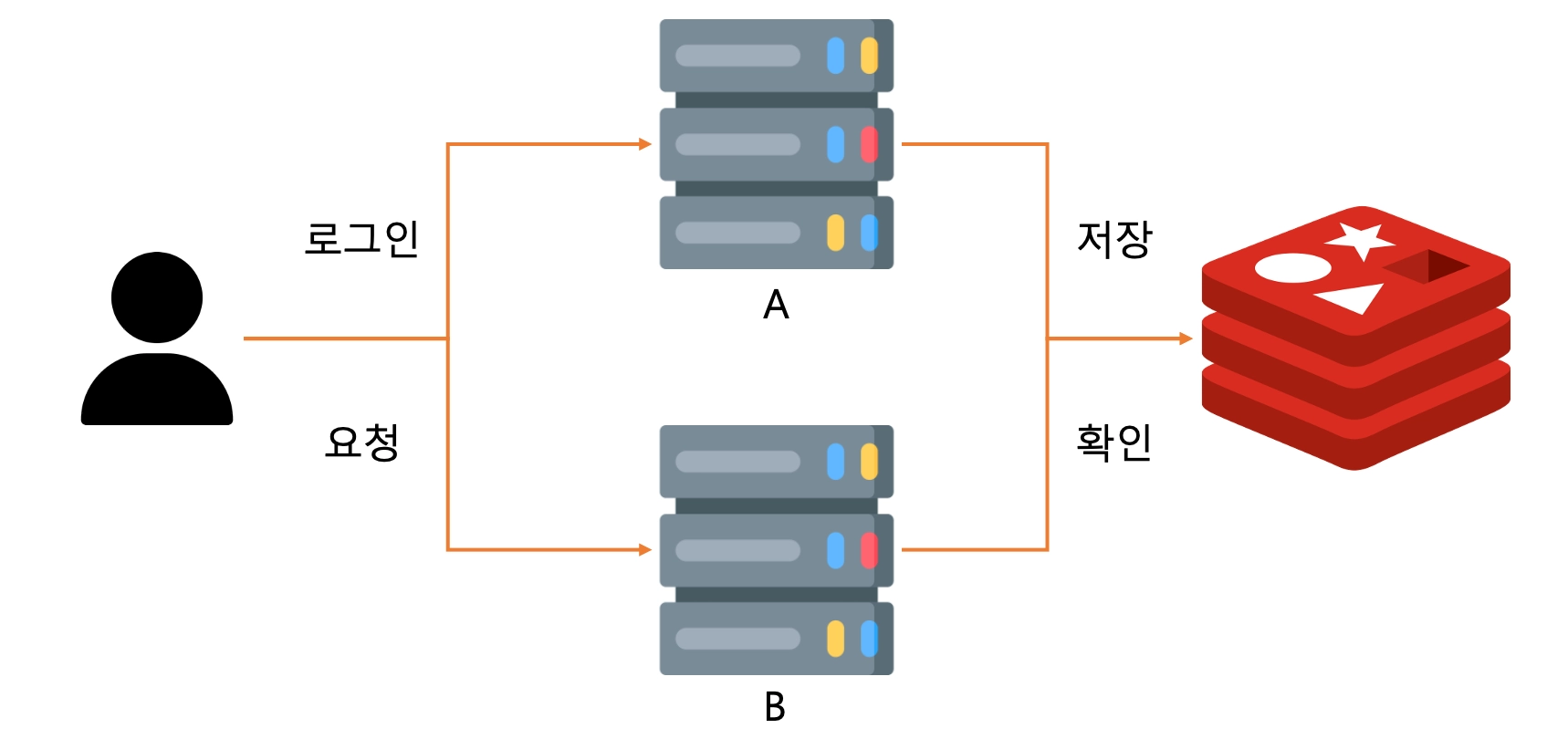
기본적으로 사용자를 구분하기 위한 값은 브라우저(쿠키)에 저장되기 때문에, 사용자의 모든 요청에 해당 값이 포함됩니다. 이를 redis 데이터베이스를 사용하기 위한 Key로서 활용하면 여러 프로세스에서 사용자 정보를 공유하기 용이합니다.
비동기 요청 처리
Redis와 RabbitMQ를 함깨 활용하여, RabbitMQ로 요청을 전달하고 Redis에 응답을 저장하는 방식으로 사용자의 요청을 비동기 처리하는 방식입니다. 사용자의 요청을 직접적으로 처리하는데 걸리는 시간이 긴 기능의 경우, 실제 사용자의 요청을 받는 Endpoint 역할을 하는 서버가, 앞서 RabbitMQ에서 하였던 Worker Queue를 활용하여 다수의 Worker 프로세스로 전달을 하게 됩니다.
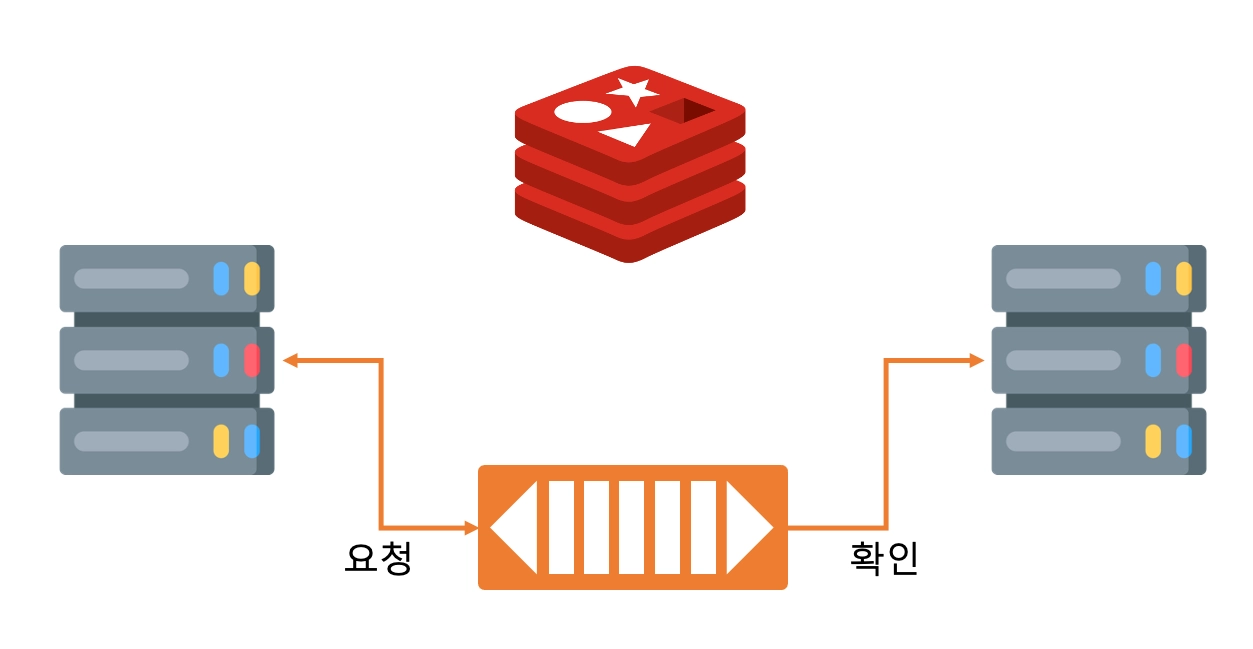
그림에서 왼쪽이 사용자의 요청을 받는 역할을 하게되면, Message Broker에 요청에 대한 정보를 저장한 이후 임의의 Worker 프로세스가 처리하도록 기다리게 됩니다. 이 시점에서 사용자의 요청을 받은 Endpoint 서버의 자원은 다시 활용할 수 있는 상태가 됩니다.
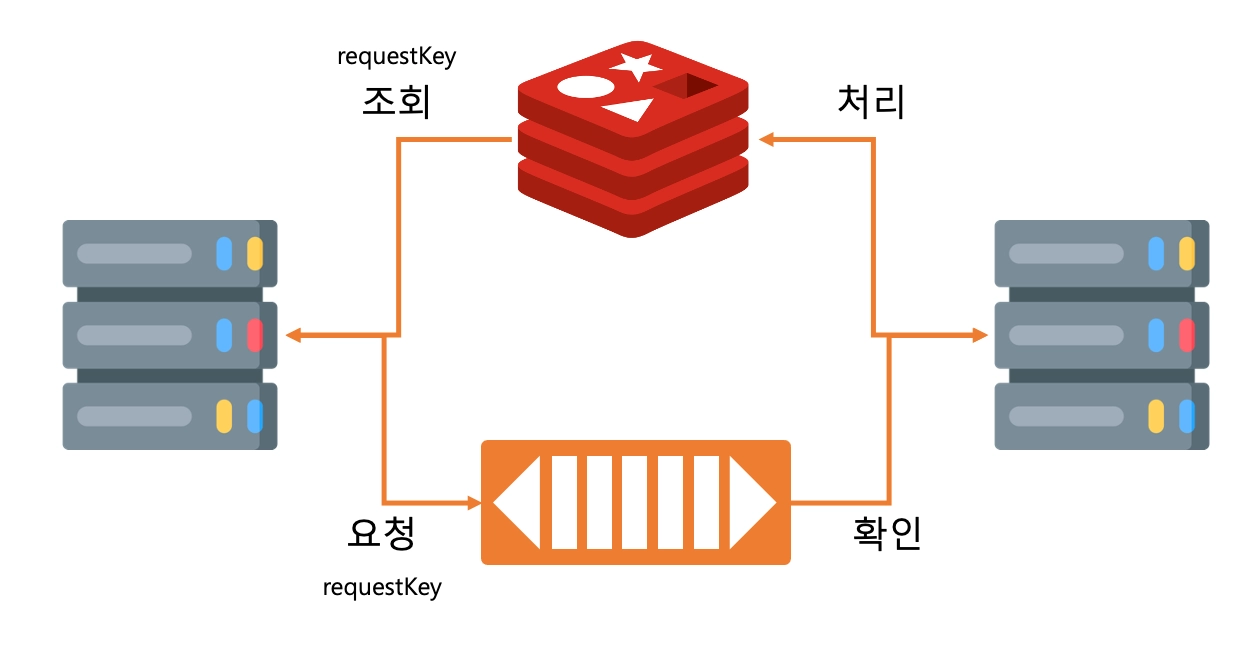
RabbitMQ가 직접적으로 응답을 하는 역할을 하지 못하기 때문에 Redis를 활용해 응답을 저장합니다. 이때 어떤 요청에 대한 응답인지를 확인하기 위한 requestKey 와 같은 부수적 데이터도 함깨 전달하여, Redis의 Key로서 활용하게 됩니다.
Redis 의존성
Redis와 RabbitMQ를 이용해서 비동기로 요청을 처리하고, 결과를 받아와 봅시다.

Redis 같은 경우 위의 의존성을 설정하면 Initialzr가 자동으로 잡아주나, 현재 spring boot starter에서 사용하는 redis client의 경우 celery이기 때문에, 좀더 흔히 사용되는 Jedis를 활용하기 위해 build.gradle 을 조금 수정해 줍시다. 추가로 데이터를 JSON 형태로 주고받고 해석하기 위해 gson도 추가해 줍니다.
implementation('org.springframework.boot:spring-boot-starter-data-redis') {
exclude group: 'io.lettuce', module: 'lettuce-core'
}
implementation 'redis.clients:jedis'
implementation 'com.google.code.gson:gson:2.9.0'
Groovy
복사
RabbitMQ - Redis
Producer 설정
Producer 자체는 많이 조정할 필요 없습니다. 실제 작업에 대한 데이터를 표현하기 위한 데이터 객체를 몇가지 선언합니다.
public class JobMessage implements Serializable {
private String jobId;
...
}
Java
복사
@RedisHash("Job")
public class JobProcess implements Serializable {
private String id;
private int status;
private String message;
private String result;
...
}
Java
복사
JobMessage 같은 경우 Worker Queue에 새로운 처리해야할 요청을 적재하는 용도로, JobProcess는 요청이 처리된 응답 데이터를 담기 위한 용도로 사용하게 됩니다. JobProcess 의 경우 Redis에서 관리를 하는 객체로 등록하기 위하여 @RedisHash() 어노테이션을 추가합니다.
@Configuration
public class ProducerConfig {
...
@Bean
public Gson gson(){
return new Gson();
}
}
Java
복사
ProducerConfig.java
private final Gson gson;
...
public String send() {
JobMessage jobMessage = new JobMessage(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend(rabbitQueue.getName(), gson.toJson(jobMessage));
logger.info("Sent Job: {}", jobMessage.getJobId());
return jobMessage.getJobId();
}
Java
복사
ProducerService.java
ProducerService 에는 Gson을 추가하고, JobMessage 객체를 JSON String의 형태로 변환하여 전송을 하도록 조정을 해줍니다.
Consumer 설정
Producer에서 만든 JobMessage와 JobProcess 객체는 Conusmer에서도 동일하게 사용합니다. 객체의 변수 등을 기준으로 JSON 데이터를 주고받는 것이기 때문에 동일한 이름의 변수로 정의하면 됩니다. 변수 형식만 동일하면 객체 이름은 달라도 작동합니다. 객체를 해석하기 위한 Gson도, CosumerConfig 에 추가하고 ConsumerService 에서 주입해 사용하는 등 Producer와 동일하게 작성하면 됩니다. 단 JobProcess 의 @RedisHash 는 Redis에서 사용할 객체를 구분하기 위한 용도임으로 변경하면 안됩니다.
RedisRepository
Redis에 주고받을 데이터로 활용하기 위해 JPA를 활용할때 다뤘던 CrudRepository를 사용합니다.
@Repository
public interface RedisRepository extends CrudRepository<JobProcess, String> {}
Java
복사
CrudRepository 를 선언할 때, 앞쪽의 객체는 이 Repository에서 사용할 Entity, 뒤쪽은 조회하기 위한 ID 입니다. 관계형 데이터베이스가 아닌, 특정 문자열 Key 를 사용해 데이터를 특징짓는 Redis인 만큼, String 을 ID로 활용합니다.
이렇게 정의된 RedisRepository 는 JPA에서 사용하듯이 사용할 수 있습니다.
private final RedisRepository redisRepository;
private final Gson gson;
public ConsumerService(
@Autowired RedisRepository redisRepository,
@Autowired Gson gson
) {
this.redisRepository = redisRepository;
this.gson = gson;
}
Java
복사
ConsumerService.java
이는 ProcuderService에서도 동일하게 정의하고 사용할 수 있습니다.
Redis에 결과 적재
ConsumerService 의 receive 함수의 내부를 구성해 봅시다.
@RabbitHandler
public void receive(String message) throws InterruptedException {
String jobId = "";
try {
JobMessage newJob = gson.fromJson(message, JobMessage.class);
jobId = newJob.getJobId();
logger.info("Received Job: {}", jobId);
JobProcess jobProcess = new JobProcess();
jobProcess.setId(newJob.getJobId());
jobProcess.setMessage("Job being processed");
jobProcess.setStatus(1);
jobProcess.setResult("");
redisRepository.save(jobProcess);
} catch (RuntimeException e){
throw new AmqpRejectAndDontRequeueException(e);
}
Thread.sleep(5000);
JobProcess jobProcess = redisRepository.findById(jobId).get();
jobProcess.setId(jobId);
jobProcess.setMessage("Finished");
jobProcess.setStatus(0);
jobProcess.setResult("Success");
redisRepository.save(jobProcess);
logger.info("Finished Job: {}", jobId);
}
Java
복사
ConsumerService.java
JobMessage 를 정상적으로 해석한다면, 해당 jobId 를 기준으로 JobProcess 객체를 만들고 1차적으로 Redis에 저장합니다. 이는 현재의 요청이 아직 처리 중이라는 것을 알리기 위해서 입니다.
이후 Thread.sleep(5000) 을 통해 처리에 시간이 걸리는 현상을 흉내낸 뒤에, 동일한 jobId 를 기준으로 처리가 완료되었음을 알려주도록 해당 객체를 업데이트 합니다.
Redis에서 결과 회수
이제 실제 결과를 받기 위한 Producer 기능을 추가합시다. 위에서 언급한데로 RedisRepository를 동일하게 작성해 주고, 활용하기 위한 RedisService 를 구현해 줍니다.
@Service
public class RedisService {
private final RedisRepository redisRepository;
public RedisService(
@Autowired RedisRepository redisRepository
) {
this.redisRepository = redisRepository;
}
public JobProcess retrieveJob(String jobId) {
Optional<JobProcess> jobProcess = this.redisRepository.findById(jobId);
if (jobProcess.isEmpty()) {
throw new ResponseStatusException(HttpStatus.NOT_FOUND);
}
return jobProcess.get();
}
}
Java
복사
RedisService.java
이제 Controller에 RequestMapping 을 추가합니다.
private final ProducerService producerService;
private final RedisService redisService;
public ProducerController(
@Autowired ProducerService producerService,
@Autowired RedisService redisService
) {
this.producerService = producerService;
this.redisService = redisService;
}
...
@GetMapping("/{jobId}")
public JobProcess getResult(@PathVariable("jobId") String jobId){
return redisService.retrieveJob(jobId);
}
Java
복사
ProducerController.java
PathVariable 로 jobId 를 받고, 해당 Job ID를 기준으로 Redis에서 결과를 조회하도록 합니다.
테스트를 할때는 브라우저에서만 진행해도 됩니다. 첫번째 / 요청은 작업을 생성해서 RabbitMQ를 거쳐 Consumer로 전달되고, JobId를 반환합니다. 이후 /{jobId} 로 요청을 보내면 해당 요청의 결과를 받아올 수 있습니다.

한계
여기서 비동기 형식으로 요청을 처리하는데, API를 사용하는 Frontend가 명확하게 사용법을 따라야 한다는 문제가 존재합니다. API로 직접적인 사용을 허가하게 될 경우, 사용자의 요청 빈도, 마무리된 요청의 정리, 응답을 회수하지 않는 요청등에 대한 관리가 더욱 정교하게 됩니다.
