
알고리즘 - Hash
Hash란?
•
임의의 크기를 가진 데이터를 고정적인 크기의 데이터로 변화시켜서 저장하는 자료구조 입니다.
•
hash는 인덱스,위치 등으로 데이터를 저장하거나 찾을 수 있습니다.
•
다른 자료구조에 비교해서 해쉬는 key값의 배열의 인덱스로 데이터가 저장되기 때문에 데이터를 바로 저장하거나 찾는 것을 빠른 속도로 처리 할 수 있습니다.
Hash는 언제 사용할까?
•
Key를 사용해서 문자열 문제를 풀어야 하는 경우에 사용 됩니다.
•
Hash는 Stack만큼 일상적으로 많이 사용된다. Map, Json 등 key 와 value 를 이용하는 모든 자료구조에 사용 됩니다.
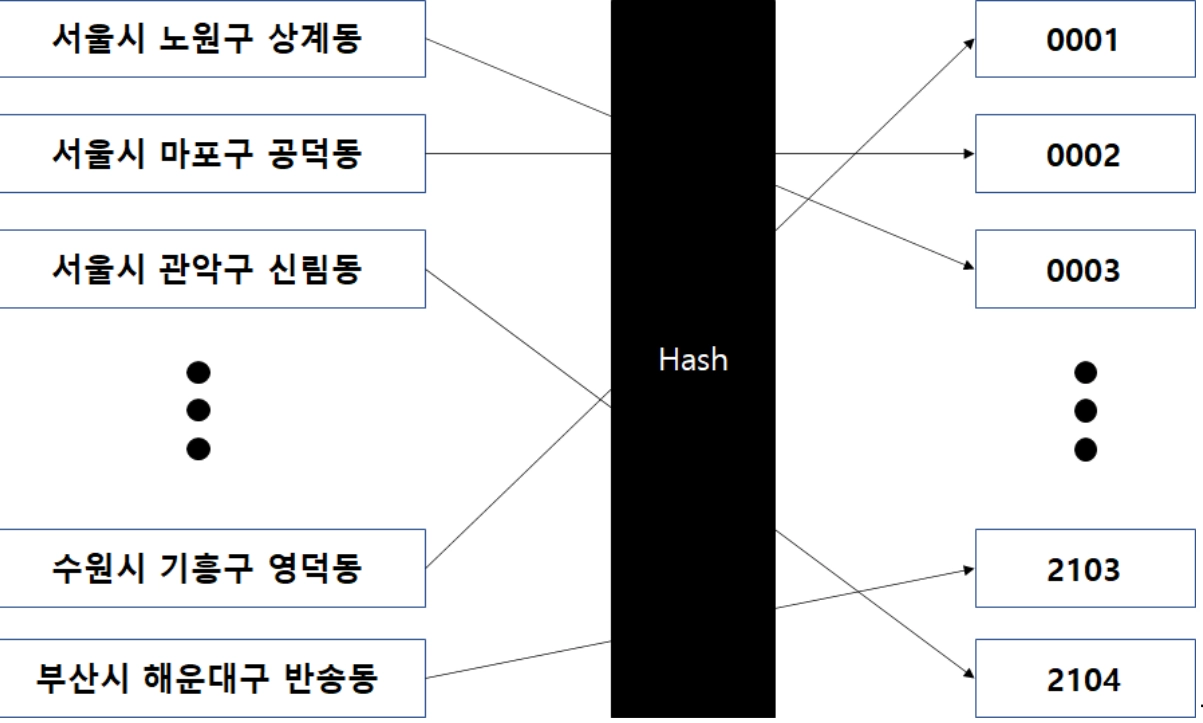
Hash의 속도 O(1)
•
함수에서 리턴된 값을 가지고 배열에 접근 하기 때문에 속도가 O(1)이 나옵니다.
•
key 를 넣으면 일정한 숫자가 리턴되는 함수가 hash 함수이고 데이터를 저장하고 불러올때 hash 함수를 사용 합니다.
Hash를 안쓰면?
하나씩 모두 찾아가야 합니다. 속도가 Max,Min과 같은 O(N) . 하나씩 데이터를 비교해서 찾아야하는 방법이 유일한 해결 방법이면 어쩔수 없겠지만 Hash 같이 충분이 효율적인 해결 방법이 있는데 사용하지 않는다면 속도적으로 비효율적 입니다.
Hash  특정값을 리턴하는 메서드
특정값을 리턴하는 메서드
특정값을 리턴하는 메서드 HashTable Hash를 사용해서 값에 접근하는 자료구조
Hash를 사용해서 값에 접근하는 자료구조 Hash Function 이란?
•
임이의 길이의 데이터를 입력 받아 일정한 길이의 비트열로 반환시켜주는 함수 입니다.
•
해시 함수는 key 값을 고정된 길이의 hash로 변환하는 역할을 합니다. 그리고 이 변환하는 과정을 해싱 (hasing) 이라고 합니다. 또는 매핑 과정 이라고 합니다.
•
문자열을 받아서 숫자를 반환하는 함수, 함수는 문자열에 숫자를 할당 합니다.
•
서로 다른 키와 같은 해시가 되는 경우를 해시 충돌이라고 하는데 해시 충돌을 일으키는 확률을 최대한 줄이는 함수를 만드는 것이 매우 중요 합니다.
해싱 과정 ( Hasing) : 키 (key) 해시 함수 (hash function) 해시 값 (Hash value)
해시 함수 (hash function) 해시 값 (Hash value)•
키 (key) : 매핑 전 원래 데이터의 값
•
해시값 : 매핑 후 데이터의 값
Hash Table:
해시 함수를 사용하여 키를 해시 값으로 매핑하고,이 해시값을 인덱스 또는 주소 삼아 value 를 key 와 함께 저장하는 자료구조 입니다.
Hash 구현
처음 구조 잡기 코드
public class HashFunction {
public int hash(String key) {
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
System.out.println(c);
}
return 0;
}
public static void main(String[] args) {
HashFunction hashFunction = new HashFunction();
hashFunction.hash("heejun");
}
}
Java
복사
핵심 로직1 입력받은 key를 한 글자씩 ascii code로 변경하는 코드
입력받은 key를 한 글자씩 ascii code로 변경하는 코드 public class HashFunction {
public int hash(String key) {
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
int ascii = c;
System.out.printf("%s %d\n" ,c, ascii);
}
return 0;
}
public static void main(String[] args) {
HashFunction hf = new HashFunction();
hf.hash("heejun");
}
}
Java
복사
ascii 코드들을 모두 합칩니다.
public int hash(String key) {
int asciiSum = 0;
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
int ascii = c;
System.out.printf("%s %d\n" ,c, ascii);
asciiSum += ascii;
}
System.out.println("asciiSum:" + asciiSum);
return 0;
}
public static void main(String[] args) {
HashFunction hf = new HashFunction();
hf.hash("heejun");
}
}
Java
복사
Hash 함수 완성
public class HashFunction {
public int hash(String key) {
int asciiSum = 0;
for (int i = 0; i < key.length(); i++) {
asciiSum += key.charAt(i);
}
return asciiSum % 90;
}
public static void main(String[] args) {
HashFunction hashFunction = new HashFunction();
int result = hashFunction.hash("heejun");
System.out.println(result);
}
}
Java
복사
Hash Table 구현
hash()함수를 이용하고, size가 들어갑니다.
public class HashTable {
private int size = 10000;
public HashTable() {
}
public HashTable(int size) {
this.size = size;
}
public int hash(String key) {
int asciiSum = 0;
for (int i = 0; i < key.length(); i++) {
asciiSum += key.charAt(i);
}
return asciiSum % size;
}
public static void main(String[] args) {
String[] names = new String[]{"DongyeonKang", "SubinKang", "KwanwunKo",
"HyunseokKo", "KyoungdukKoo", "YeonjiGu", "SoyeonKown", "OhsukKwon",
"GunwooKim", "KiheonKim", "NayeongKim", "DohyeonKim", "MinkyoungKim",
"MinjiKim", "SanghoKim", "SolbaeKim", "YejinKim", "EungjunKim",
"JaegeunKim", "JeonghyeonKim", "JunhoKim", "JisuKim", "kimjinah",
"HaneulKim", "HeejungKim", "KimoonPark", "EunbinPark", "JeongHoonPark",
"JeminPark", "TaegeunPark", "JiwonBae", "SeunggeunBaek", "JihwanByeon",
"HeungseopByeon", "JeongHeeSeo", "TaegeonSeo", "SeeYunSeok", "SuyeonSeong",
"SeyoelSon", "MinjiSong", "JinwooSong", "hyunboSim", "SominAhn", "JiyoungAhn",
"ChangbumAn", "SoonminEom", "HyeongsangOh", "SuinWoo", "JuwanWoo", "InkyuYoon",
"GahyunLee", "DaonLee", "DohyunLee", "SanghunLee", "SujinLee", "AjinLee", "YeonJae",
"HyeonjuLee", "HakjunYim", "SeoyunJang", "SeohyeonJang", "JinseonJang", "SujinJeon",
"SeunghwanJeon", "DaehwanJung", "JaeHyunJeung", "HeejunJeong", "GukhyeonCho", "MunjuJo",
"YejiJo", "ChanminJu", "MinjunChoi", "SujeongChoi", "SeunghoChoi", "AyeongChoi",
"GeonjooHan", "JinhyuckHeo", "MinwooHwang", "SieunHwang", "JunhaHwang"};
HashTable ht = new HashTable();
Set<Integer> nameSet = new HashSet<>();
for (int i = 0; i < names.length; i++) {
nameSet.add(ht.hash(names[i])); // hash 함수로 변환하여 반환된 값을 nameSet에 추가
}
System.out.printf("%s %s", names.length, nameSet.size());
}
}
Java
복사
return asciiSum % size; 로 한 이유
1.지정된 크기의 배열에 값을 저장 하기 때문 입니다.
2.size로 정한 배열의 어딘가로 가도록 하기 위함
ex) 배열 사이즈가 1000이라면 asciiSum % 1000을 하면 0~999 사이의 값이 나와서 벗어나지 않음
Size를 정하는 기준
어떤 공식이 있지는 않습니다.
Hash충돌이 나지 않으면서도 메모리를 너무많이 쓰지 않는 크기로 정합니다.
해시 테이블을 설계하고자 할 때 가장 먼저 고려해야 할 것은 해시 테이블의 크기 입니다. 해시 테이블의 크기는 이상적으로 크면 클수록 좋습니다. 해시 충돌 문제를 최소화하기 위해서입니다. 하지만 컴퓨터의 메모리는 무한대가 아니기 때문에 메모리를 효율적으로 활용하기 위해 무작정 큰 사이즈를 잡기보다는 실제 원본 데이터의 크기를 보고 결정하는 것이 바람직 합니다.
데이터가 저장되는 과정
DongyeonKang → hash(name) → 20번 방을 배정 받음 → 20Idx에 데이터를 저장
.insert(DongyeonKang, 1) // 20 번 방에 1을 저장
... | 19 | 20 | 21 | .. | .. | |||
1 |
데이터를 꺼내는 과정
.search(DongyeonKang) // key만 넣습니다..
DongyeonKang → hash(name) → 20
return arr[20]; // 1이 출력 된다.
Hash Table 클래스의 멤버변수,생성자 생성
public class HashTable {
private int size = 10000;
private int[] table = new int[size];
public HashTable() {
}
public HashTable(int size) {
this.size = size;
this.table = new int[size];
}
Java
복사
insert 메서드 설계 : key,value를 입력 받도록 설계
public void insert(String key, Integer value) {
int hashCode = hash(key);
this.table[hashCode] = value;
System.out.println(key + " " + hashCode + "방에 저장이 완료 되었습니다.");
}
Java
복사
잘 저장되는지 실행
HashTable ht = new HashTable(200);
for (int i = 0; i < names.length; i++) {
ht.insert(names[i], ht.hash(names[i]))
}
Java
복사

위의 사진과 같이 결과가 나온다면 잘 저장 되는 것 입니다.
search() 설계 및 구현 :
.search(key) 형태로 값을 받아 옵니다.
this.table[hash(key)] key를 다시 hash로 만들어서 array에서 값을 뽑아 옵니다.
public int search(String key) {
return this.table[hash(key)];
}
Java
복사
잘 되는지 확인
HashTable ht = new HashTable(200);
for (int i = 0; i < names.length; i++) {
ht.insert(names[i], ht.hash(names[i]));
}
System.out.println(ht.search("HeejunJeong"));
Java
복사

위의 사진 처럼 나온다면 성공 입니다.
