
I. 알고리즘 : 삽입 정렬
1. 강의 노트

강의 노트 : 삽입 정렬
1.
특징
a.
1번부터 시작해서(0번 아님), 들어가야 할 곳에 insert하는 정렬
b.
어느 위치에 들어가야 하는지 결정하기 때문에 삽입(Insertion) 정렬이라고 한다.
2.
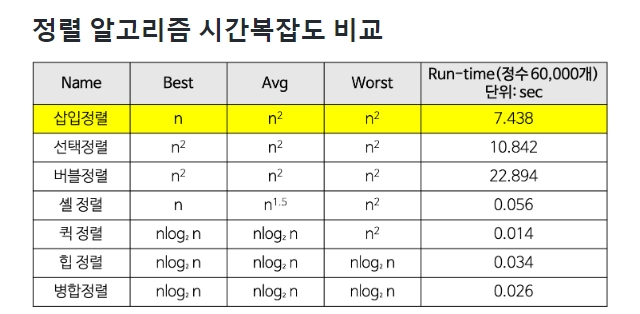
단점 : 뒤로 가는 구간이 있다. 느리다 O(N^2)
3.
장점 : for문 뒤로 가는 것 연습이 가능함.
4.
칠판코딩 : 모르는 상태에서 어떻게 생각을 떠올리는지 보기 위한 목적
삽입 정렬 진행 과정
a.
기본 틀 작성
•
삽입 정렬이 들어갈 sort 메소드를 만들었다.
코드
b. Swap 메소드
•
버블 정렬 알고리즘과 같이 Swap 메소드를 추가하고 sort 메소드에 맨 처음 루프의 동작을 추가했다.
코드
c. 루프 i 추가
•
맨처음 루프가 아닌 모든 루프에서도 동작할 수 있도록 이중 for문을 추가했다.
코드
참고. i를 파라미터로 넘겨보는 이유 = 재귀
재귀란 자기 자신을 호출하는 것
•
반복문(while) 없이 반복해야 할 때 > 단순한 코드를 위해 사용
도전 문제 2 : 재귀 구현 코드
2. 기본 개념 보충하기
1.
삽입 정렬의 정의 및 특성
a.
정의
•
카드 놀이에서의 정렬 방식과 유사하게 작동하는 간단한 정렬 알고리즘
•
정렬된 부분과 정렬되지 않은 부분으로 나눌 수 있음
•
정렬되지 않은 부분의 값이 선택되어, 정렬된 부분에 올바른 위치에 배치됨
◦
두 번째 요소 부터 시작하여 그 앞(왼쪽)의 요소들과 비교하여 삽입할 위치를 지정한다.
b.
특성
•
이미 부분적으로 정렬된 데이터들을 정렬하는데 효과적이다
2.
삽입정렬의 동작과정
3.
삽입 정렬의 동작과정
삽입 정렬이 부분적으로 정렬된 데이터에서 효율적인 이유

•
노란색으로 표시된 부분은 5가 타겟 인덱스 일 경우 정렬 되는 방식이다.
•
5는 10과 12보다 작기 때문에 오름차순 정렬을 위해 swap 해준다.
•
여기서 중요한 것은, 4와 5도 비교가 될 텐데, 4<5 이므로 앞에 나머지 요소 [1,2,3] 과 비교 해주는 과정을 생략하고 이미 제대로 정렬되어 있다고 가정한다.
•
따라서, [1,2,3,5,6,4]와 같이 이미 부분적으로 정렬이 되어 있다면, 데이터를 교환해주는 횟수가 적어지기 때문에 효율적이다.
3.
최선의 경우 (데이터가 완전히 오름차순 정렬되어 있는 경우)•
비교 횟수
◦
이동 없이 1번의 비교만 이루어짐
◦
외부 루프: (n-1)번
◦
따라서 O(n) <빅오 표기법 기준>
최악의 경우 (데이터가 역순으로 정렬되어 있는 경우)•
비교 횟수
◦
외부 루프 안의 각 반복마다 i번의 비교 수행
◦
외부 루프: (n-1 + (n-2) + (n-3) + … + 2 + 1 = n(n-1)/2
◦
따라서, 최악의 경우는 O(n^2)
•
교환 횟수
◦
외부 루프의 각 단계 마다 (i+2)번의 이동 발생
▪
( target index, target index의 값, target index 앞에 있는 요소의 값 )
◦
n(n-1)/2 + 2(n-1) = (n^2 + 3n -4) / 2 = O(n^2)
삽입 정렬 코드
II. Hospital 프로젝트
1. write 메소드 추가
•
기존에 만들었던 sql 쿼리문을 만드는 메소드에 write메소드를 추가하여 .sql파일로 저장할 수 있도록 추가한다.
FileController.java
Main.java
•
위와 같이 메소드를 추가하여 실행시키면 다음과 같은 sql파일이 만들어진다.

테이블 비우기(Truncate Table) - 신중하게 할 것!
db에 영향이 큰 query를 날리기 전에 db를 백업하고 해야 한다.
운영서버인지 개발 서버인지 꼭 확인 하고 할 것!
2. MySQL Workbench에 insert하기
1. 파일 insert하기

•
폴더 버튼을 클릭해 열고 만들어 뒀던 sql파일을 연다.
2. insert 확인하기
SELECT count(*) FROM hospital.seoul_hospital ;
SQL
복사

•
insert된 데이터의 총 개수를 확인 할 수 있다.
III. SQL
1. 기본 쿼리문 연습하기
•
쿼리 : DB에 질문을 해서 답을 얻는 과정
•
기본 SELECT문부터 시작
SELECT subdivision, name FROM hospital.seoul_hospital;
--- hospital 데이터베이스의 seoul_hospital 테이블에서 subdivision, name 열(row) 선택
SQL
복사
조회 데이터 개수 제한 : limit
SELECT * FROM hospital.seoul_hospital limit 1000;
SQL
복사
•
원하는 수의 데이터를 불러온다.
•
limit을 걸어 데이터를 불러와야 대용량 데이터 처리를 빠르게 할 수 있다.
결과
상세 조건 : where
SELECT subdivision, name FROM seoul_hospital where subdivision = “” limit 1000;
SQL
복사
•
where절에 조건을 명시 해줌으로써, 특정 데이터만 검색해낼 수 있다.
•
select 문과 주로 사용
결과
and 조건과 like 검색
SELECT subdivision, name FROM seoul_hospital where subdivision = "" and
name like "%이비인후과%" limit 1000;
SQL
복사
•
subdivision이 비어있는 데이터 중 이름에 이비인후과가 들어있는 데이터의 subdivision과 name을 출력한다.
•
and 키워드 : A and B : A와 B의 조건을 둘 다 만족하는 경우를 표현할 때 사용
•
like 키워드 : 위와 같이 % 사이에 원하는 글자를 입력하면, 관련된 레코드를 검색해낼 수 있음.
Count
#세부 분과가 "" 이고, 병원명에 이비인후과가 포함된 name 컬럼의 수를
# 1000개 이내로 seoul_hospital 테이블에서 조회해라.
select count(name) FROM seoul_hospital
where subdivision = “” and name like “%이비인후과%” limit 1000;
SQL
복사
•
특정 조건인 데이터 개수 세기 : subdivision이 비어있는 데이터 중 이름에 이비인후과가 들어있는 데이터의 개수를 출력한다.
•
limit 키워드를 뒤에 붙혀주는 것이 좋다.
•
count(컬럼명) 함수 : 컬럼의 개수를 반환해주는 함수
Update 쿼리 by id
Update seoul_hospital set subdivision=”이비인후과”
where id = “A1100196”
SQL
복사
•
id가 "A1100196"의 subdivision을 이비인후과로 변경한다.
•
업데이트 쿼리 시 Safe 모드 해제 → 약간 금단의 영역
safe모드 해제 요약
•
대용량의 레코드 업데이트는 하지 않도록 되어 있음 (?)
•
update (테이블명) set 컬럼명 = “값” where 조건문으로 구성
•
UPDATE ~ SET 구조로 기억하기
Update 쿼리 by condition
UPDATE `likelion-db`.`seoul_hospital` SET subdivision = "이비인후과"
where subdivision = "" and name like "%이비인후과%";
SQL
복사
•
subdivision이 비어있는 데이터중 이름에 이비인후과가 들어간 모든 데이터의 subdivision을 이비인후과로 변경한다.
•
update (테이블명) set 컬럼명 = “값” where 조건문으로 구성
•
UPDATE ~ SET 구조로 기억하기
distinct
select distinct (category) from seoul_hospital;
SQL
복사
•
해당 컬럼의 가진 다양한 값을 중복을 제거해줌으로써 고유값만 나타나도록 한다.
결과
Group by, Order by
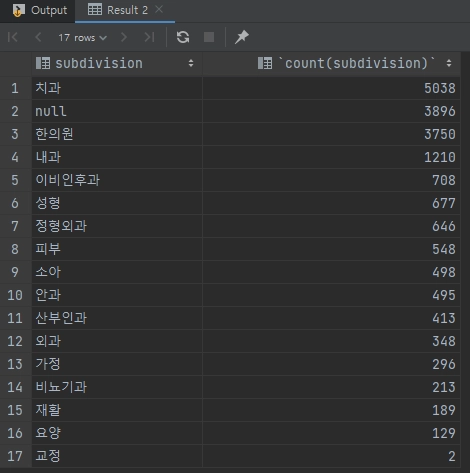
병원의 세부 분과(subDivision)를 통해 서울 시의 병원 중 무엇이 가장 많은지?
select subdivision, count(subdivision) from seoul_hospital
group by subdivision
order by count(subdivision) desc;
SQL
복사
select name, district, subdivision, count(subdivision) as cnt from seoul_hospital
where name like '%성형외과%'
group by name, district, subdivision
order by cnt desc;
SQL
복사
•
각 구별로 병원의 이름과 병원의 개수, 세부 분과를 내림차순으로 보여줌
•
order by로 각 구별 경원 개수를 내림차순 정렬
•
group by 키워드를 통해서 select 하고자 하는 컬럼명을 명시해주어야 함.
결과
2. 요구사항 분석하기
1.
병원분류명(category)이 총 몇 가지인가?
-- distinct : 고유값만 나타내는 쿼리
SELECT distinct category FROM seoul_hospital
order by category
limit 1000;
SQL
복사
2.
병원 분류(subdivision)별로 몇 개씩 있는가?
-- group by : 정렬
SELECT subdivision, count(subdivision) as cnt FROM seoul_hospital
group by subdivision
order by cnt desc
limit 1000;
SQL
복사
3.
서울 구별로 병원이 가장 많은 구는?
SELECT district, count(district) as cnt FROM seoul_hospital
group by district
order by cnt DESC;
limit 1000;
SQL
복사
4.
각 구별로 성형외과 개수
SELECT district, subdivision, count(subdivision) as cnt FROM seoul_hospital
where subdivision = “성형외과”
group by district, subdivision
order by district, subdivision, cnt
limit 1000;
SQL
복사
5.
구별로 병원이 몇 개 있는지?
SELECT district, count(district) as cnt FROM `likelion-db`.seoul_hospital
-- 특정 조건이 담긴 row를 임의로 명명해 사용 가능 (as 변수명)
group by district
order by cnt desc;
SQL
복사
실습 결과
추가 노트
•
SQL로도 히트맵을 그릴 수 있음
•
엑셀이나 sublimetext는 대용량 데이터를 다루기 적절하지 않다
