
해시
•
데이터의 관리/유지 자료구조
•
리소스 < 속도
•
임의의 크기 데이터를 고정 크기 데이터로 변환하는 것
키(Key)와 값(Value) 쌍으로 이루어진 데이터 구조로 삽입, 삭제, 조회가 평균 O(1) 시간에 수행됩니다.
기본 개념은 키를 배열에 저장하는 것으로 배열에 저장되는 위치는, 키를 ‘해시 코드’한 결과에 따라 결정됩니다.

해시코드 : 키값에 해시 함수를 적용해서 계산된 정수 값.

해시 테이블과 정렬된 배열과 다른점
1.
키가 순서대로 저장될 필요가 없다.
2.
랜덤화(특히, 해시함수)가 중심 역할을 한다.
3.
이진 탐색 트리와 비교해보면, (재해싱이 드물게 발생한다는 가정하에) 해시테이블에서의 삽입과 삭제 연산이 효율적이다.
해시 테이블의 단점
1.
해시 함수가 필요하다.
Hash 값이 충돌하는 경우
해시 함수를 돌려 나온 값이 동일할 때.
해시 테이블에서는 충돌에 의한 문제를 분리 연결법(Separate Chaining)과 개방 주소법(Open Addressing) 크게 두가지로 해결하고 있다.
분리 연결법
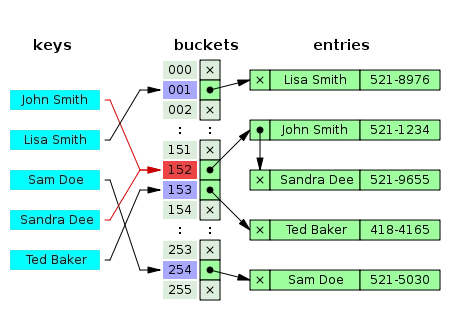
동일한 버킷의 데이터에 대해 자료구조를 활용해 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 것.
이러한 Chaining 방식은 해시 테이블의 확장이 필요없고 간단하게 구현이 가능하며, 손쉽게 삭제할 수 있다는 장점이 있다. 하지만 데이터의 수가 많아지면 동일한 버킷에 chaining되는 데이터가 많아지며 그에 따라 캐시의 효율성이 감소한다는 단점이 있다.
개방 주소법
추가적인 메모리를 사용하는 Chaining 방식과 다르게 비어있는 해시 테이블의 공간을 활용하는 방법
1.
Linear Probing: 현재의 버킷 index로부터 고정폭 만큼씩 이동하여 차례대로 검색해 비어 있는 버킷에 데이터를 저장한다.
2.
Quadratic Probing: 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를 들어 처음 충돌이 발생한 경우에는 1만큼 이동하고 그 다음 계속 충돌이 발생하면 2^2, 3^2 칸씩 옮기는 방식이다.
3.
Double Hashing Probing: 해시된 값을 한번 더 해싱하여 해시의 규칙성을 없애버리는 방식이다. 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 하게 된다.
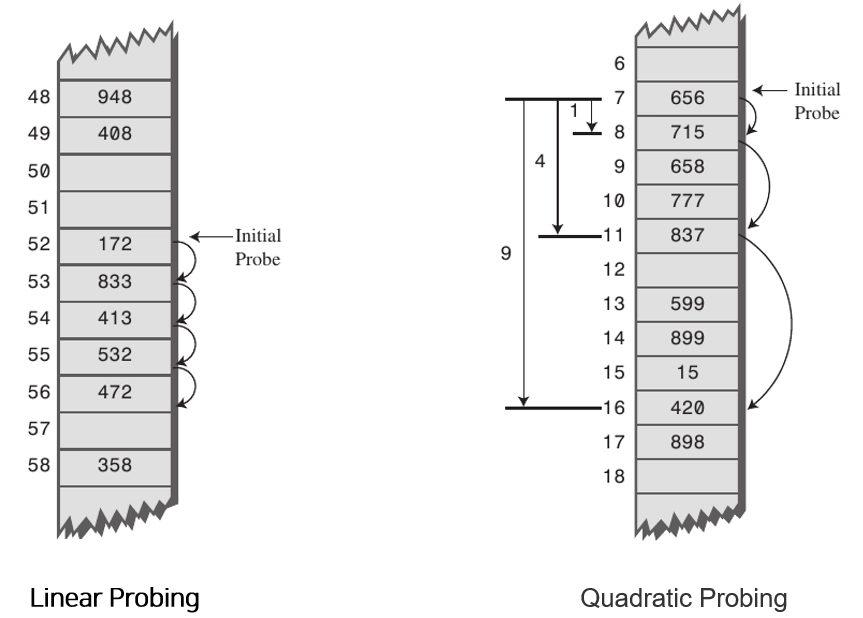
Open Addressing에서 데이터를 삭제하면 삭제된 공간은 Dummy Space로 활용되는데, 그렇기 때문에 Hash Table을 재정리 해주는 작업이 필요하다고 한다.
코드
import java.util.LinkedList;
public class HashTable {
class Node {
String key;
String value;
public Node(String key, String value) {
this.key = key;
this.value = value;
}
String value() {
return value;
}
void value(String value) {
this.value = value;
}
}
// Node형 연결리스트로 선언
LinkedList<Node>[] data;
// 자신을 호출하면서 크기를 지정하여 선언
public HashTable(int size) {
this.data = new LinkedList[size];
}
// Key값을 통해 HashCode 생성 - 아스키코드이용
int gethashCode(String key) {
int hashcode = 0;
for (char c : key.toCharArray())
hashcode += c;
return hashcode;
}
// HashCode를 이용해서 Index를 지정
int convertToIndex(int hashcode) {
return hashcode % data.length;
}
Node searchKey(LinkedList<Node> list, String key) {
if (list == null) return null;
for (Node node : list) {
if (node.key.equals(key)) {
return node;
}
}
return null;
}
// Key를 통한 값 저장
void set(String key, String value) {
int index = convertToIndex(gethashCode(key));
LinkedList<Node> list = data[index];
// 없으면 저장
if (list == null) {
list = new LinkedList<Node>();
data[index] = list;
}
Node node = searchKey(list, key);
if (node == null)
list.addLast(new Node(key, value));
else
node.value(value);
System.out.println("hashcode : " + gethashCode(key) + ", index : " + index + ", ");
}
// key를 통한 값 호출
String get(String key) {
int index = convertToIndex(gethashCode(key));
LinkedList<Node> list = data[index];
if (list == null)
return "Not Found";
else {
for (Node n : list) {
if (n.key.equals(key))
return n.value;
}
return null;
}
}
}
Java
복사
Hash Map
Map은 키와 값으로 구성된 Entry객체를 저장하는 구조를 가지고 있는 자료구조입니다.
키와 값은 모두 객체이며. 값은 중복 저장될 수 있지만 키는 중복 저장될 수 없습니다.
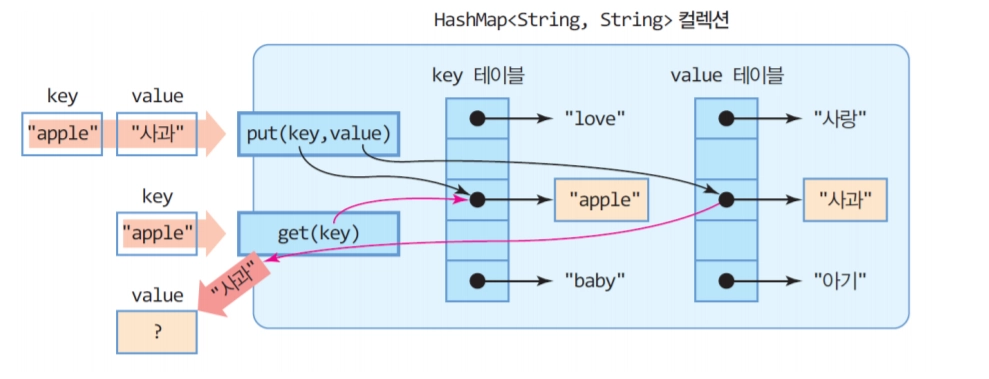
HashMap은 해시 함수를 통해 '키'와 '값'이 저장되는 위치를 결정하므로, 사용자는 그 위치를 알 수 없고, 삽입되는 순서와 들어 있는 위치 또한 관계가 없습니다.
사용법
HashMap<String,String> map1 = new HashMap<String,String>();//HashMap생성
HashMap<String,String> map2 = new HashMap<>();//new에서 타입 파라미터 생략가능
HashMap<String,String> map3 = new HashMap<>(map1);//map1의 모든 값을 가진 HashMap생성
HashMap<String,String> map4 = new HashMap<>(10);//초기 용량(capacity)지정
HashMap<String,String> map5 = new HashMap<>(10, 0.7f);//초기 capacity,load factor지정
HashMap<String,String> map6 = new HashMap<String,String>(){{//초기값 지정
put("a","b");
}};
Java
복사
HashMap<Integer,String> map = new HashMap<>();//new에서 타입 파라미터 생략가능
map.put(1,"사과"); //값 추가
map.remove(1); //key값 1 제거
map.clear(); //모든 값 제거
System.out.println(map); //전체 출력 : {1=사과, 2=바나나, 3=포도}
System.out.println(map.get(1));//key값 1의 value얻기 : 사과
//entrySet() 활용
for (Entry<Integer, String> entry : map.entrySet()) {
System.out.println("[Key]:" + entry.getKey() + " [Value]:" + entry.getValue());
}
//KeySet() 활용
for(Integer i : map.keySet()){ //저장된 key값 확인
System.out.println("[Key]:" + i + " [Value]:" + map.get(i));
}
//entrySet().iterator()
Iterator<Entry<Integer, String>> entries = map.entrySet().iterator();
while(entries.hasNext()){
Map.Entry<Integer, String> entry = entries.next();
System.out.println("[Key]:" + entry.getKey() + " [Value]:" + entry.getValue());
}
//keySet().iterator()
Iterator<Integer> keys = map.keySet().iterator();
while(keys.hasNext()){
int key = keys.next();
System.out.println("[Key]:" + key + " [Value]:" + map.get(key));
}
Java
복사
https://coding-factory.tistory.com/556
HashSet
Set은 객체를 중복을 자동으로 제거하기 때문에 중복해서 저장할 수 없고 하나의 null 값만 저장할 수 있습니다. 또한 저장 순서가 유지되지 않습니다.
HashSet의 경우 정렬을 해주지 않습니다.
Set은 위 그림과 같이 주머니 형태로 되어 있습니다. 비선형 구조이기에 순서가 없으며 그렇기에 인덱스도 존재하지 않습니다. 그렇기에 값을 추가하거나 삭제할 때에는 내가 추가 혹은 삭제하고자 하는 값이 Set 내부에 있는지 검색 한 뒤 추가나 삭제를 해야 하므로 속도가 List구조에 비해 느립니다.
중복을 걸러내는 과정
HashSet은 객체를 저장하기 전에 먼저 객체의 hashCode()메소드를 호출해서 해시 코드를 얻어낸 다음 저장되어 있는 객체들의 해시 코드와 비교한 뒤 같은 해시 코드가 있다면 다시 equals() 메소드로 두 객체를 비교해서 true가 나오면 동일한 객체로 판단하고 중복 저장을 하지 않습니다.
(TreeSet의 경우 정렬이 되며 JDK 1.4부터 제공하는 LinkedHashSet의 경우 저장 순서를 유지)
사용법
HashSet<Integer> set1 = new HashSet<Integer>();//HashSet생성
HashSet<Integer> set2 = new HashSet<>();//new에서 타입 파라미터 생략가능
HashSet<Integer> set3 = new HashSet<Integer>(set1);//set1의 모든 값을 가진 HashSet생성
HashSet<Integer> set4 = new HashSet<Integer>(10);//초기 용량(capacity)지정
HashSet<Integer> set5 = new HashSet<Integer>(10, 0.7f);//초기 capacity,load factor지정
HashSet<Integer> set6 = new HashSet<Integer>(Arrays.asList(1,2,3));//초기값 지정
Java
복사
HashSet<Integer> set = new HashSet<Integer>(Arrays.asList(1,2,3));//HashSet생성
set.add(4); //값 추가
set.remove(4);//값 1 제거
set.clear();//모든 값 제거
System.out.println(set.size());//크기 구하기
/* 값 출력 */
Iterator iter = set.iterator(); // Iterator 사용
while(iter.hasNext()) {//값이 있으면 true 없으면 false
System.out.println(iter.next());
}
/* 값 검색 */
System.out.println(set.contains(1)); //set내부에 값 1이 있는지 check : true
Java
복사
Open Addressing에서 데이터를 삭제하면 삭제된 공간은 Dummy Space로 활용되는데, 그렇기 때문에 Hash Table을 재정리 해주는 작업이 필요하다고 한다.
Plain Text
복사
출처:
[MangKyu's Diary:티스토리]
Open Addressing에서 데이터를 삭제하면 삭제된 공간은 Dummy Space로 활용되는데, 그렇기 때문에 Hash Table을 재정리 해주는 작업이 필요하다고 한다.
