

.png&blockId=18f00b21-a9bc-4e35-aeb8-ecb07bddb89a)
인덱스 Index
DBMS에서 정해준 방식대로 데이터를 구조화 해 데이터가 어디에 있는 지를 저장한다.
스토리지에서 원하는 데이터를 찾는 것을 돕는 도구
책 뒤에 키워드와 페이지 번호가 있는 용어집과 비슷하다
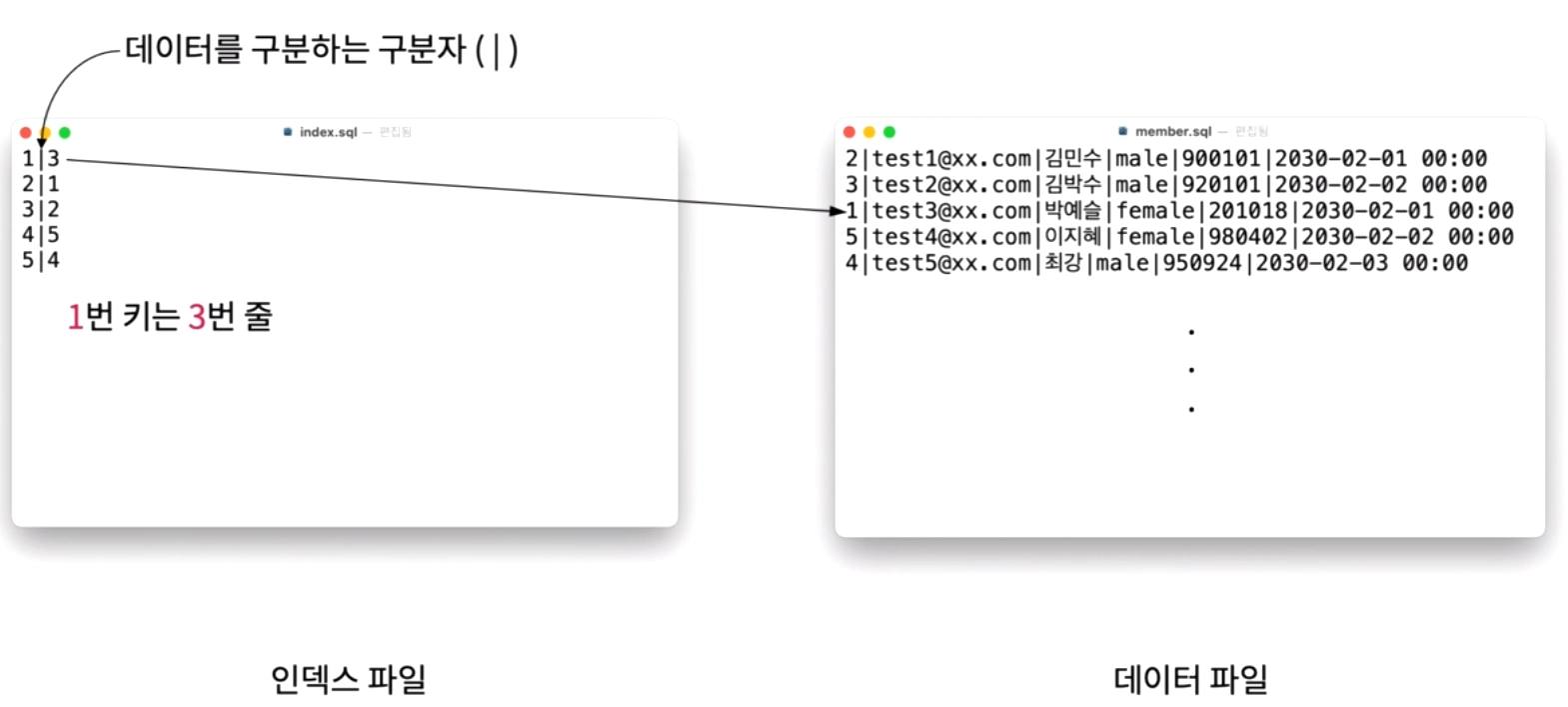
특정 행을 찾기 위해서는 첫번째 행부터 전체 테이블을 읽어야 하는데, 인덱스가 있으면 데이터 파일을 모두 탐색하지 않고, 특정 레코드를 빠르게 찾을 수 있다
인덱스는 저장공간을 효율적으로 사용할 수 있게 해준다
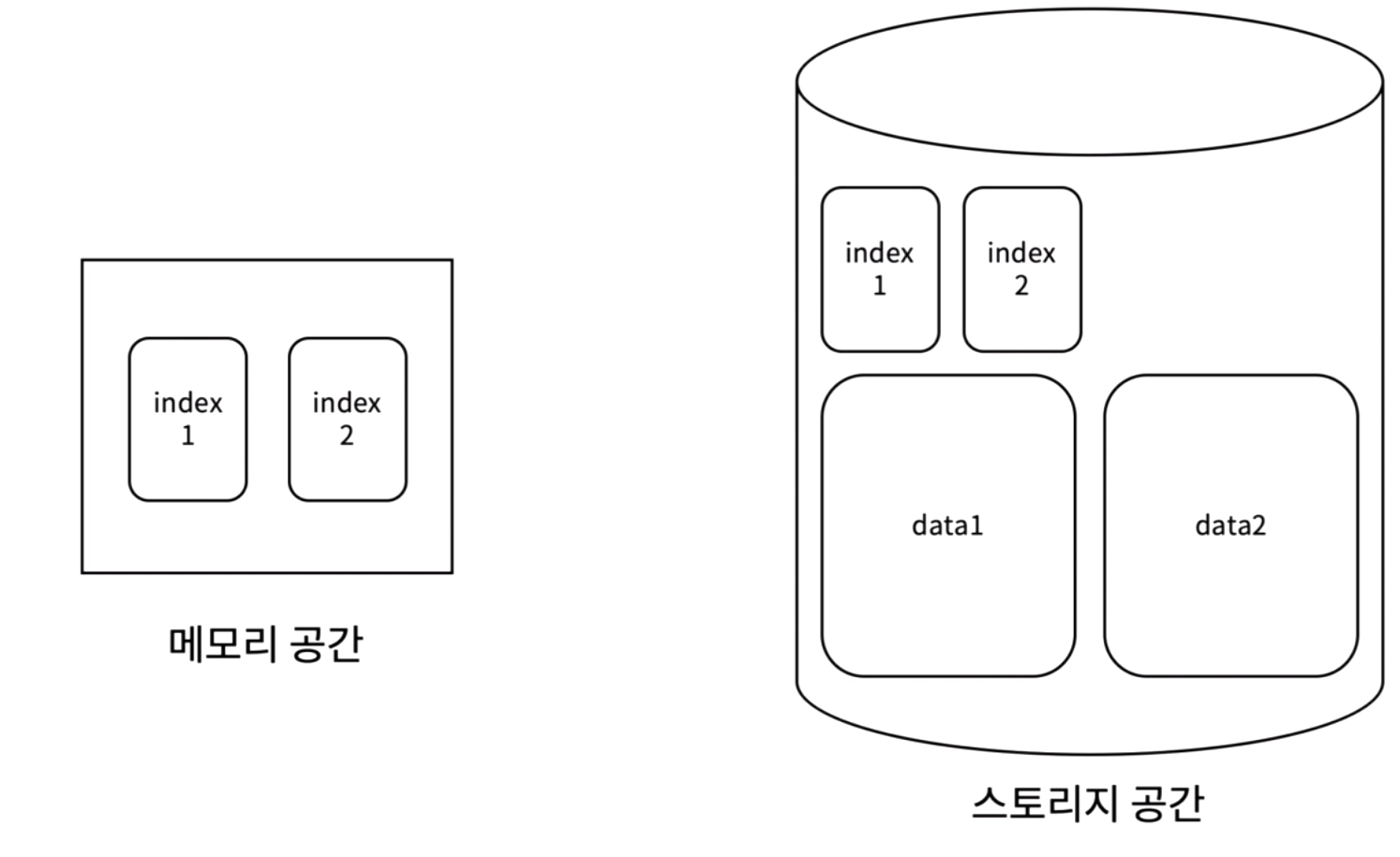
스토리지 공간보다 작은 메모리 공간에는 모든 데이터를 저장할 수 없지만, 인덱스 파일은 데이터 파일 보다 작기 때문에 메모리에 저장해서 사용할 수 있다.
인덱스 파일이 없을 때
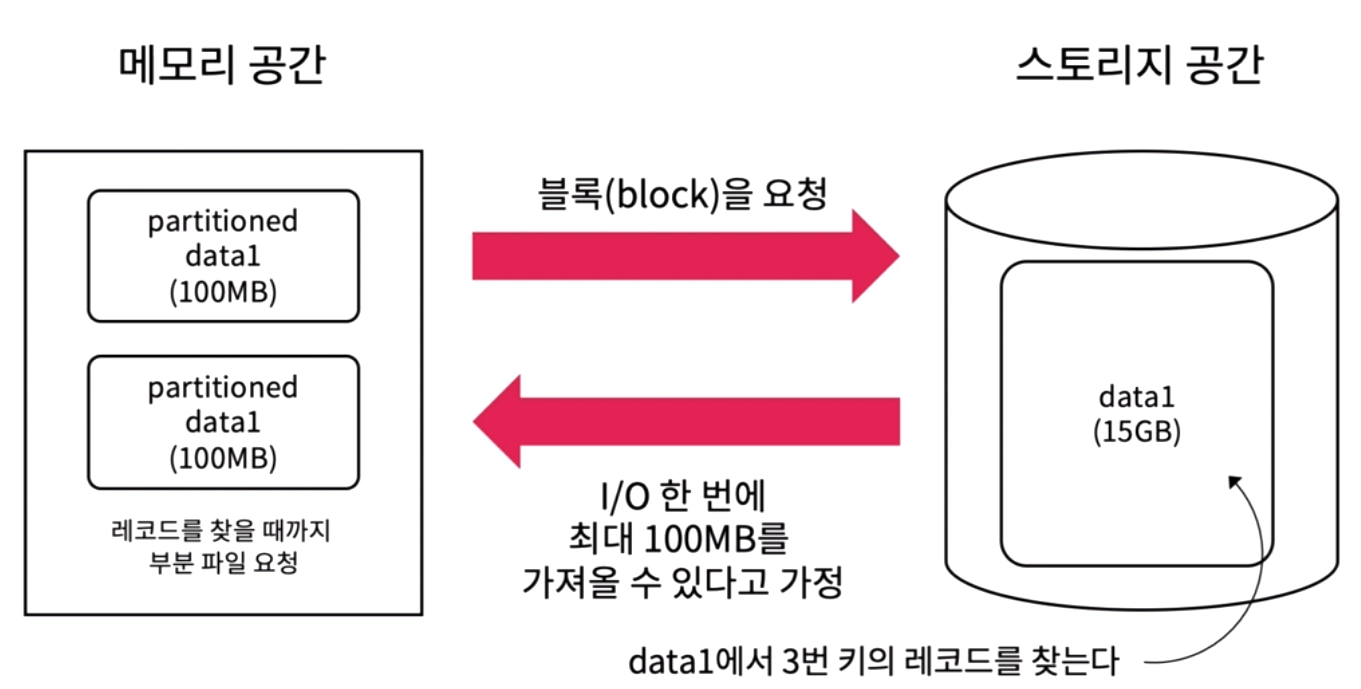
부분적으로 스토리지에서 데이타를 요청해 특정 데이터를 찾고, 없으면 다시 데이터를 요청한는 것을 반복한다
인덱스 파일이 있을 때
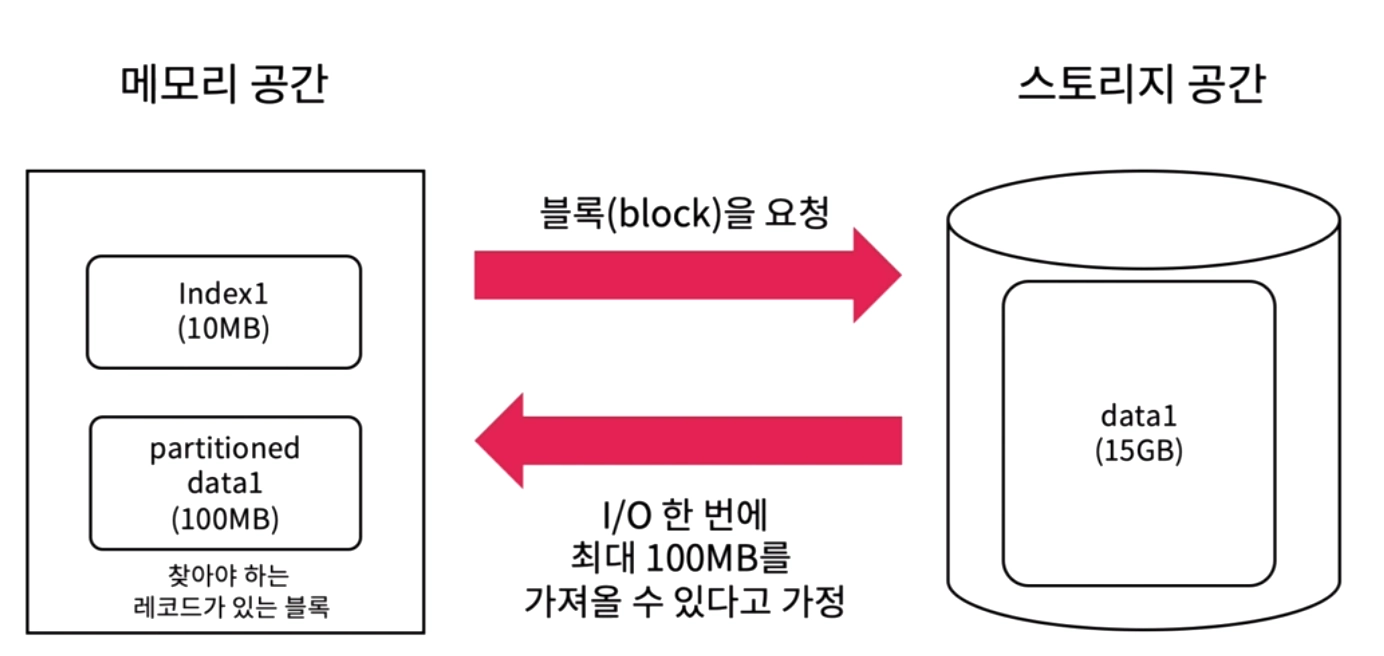
인덱스 파일 내에서 데이터를 찾고, 데이터가 있는 블록을 요청해 블록 안에서 데이터를 찾는다
I/O 빈도를 줄임으로써 효율을 증가
인덱스의 종류
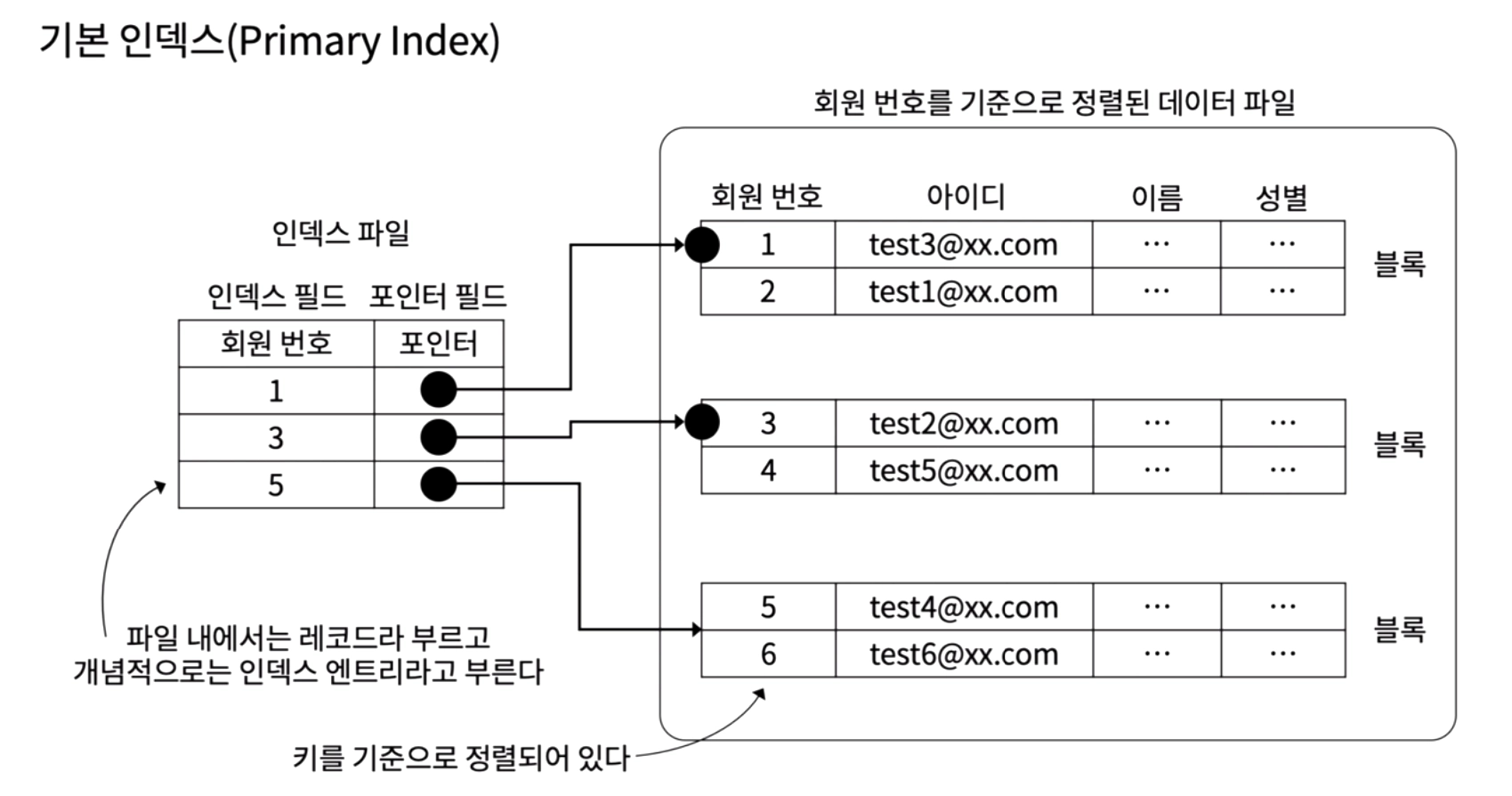
1. 기본 인덱스 Primary Index
1.
인덱스 필드: 기본키
2.
포인터 필드: 블록의 위치값
•
인덱스 필드로 정렬되어있다
•
인덱스 파일의 한 행을 인덱스 엔트리라고 부르고, 인덱스 엔트리마다 하나의 블록과 연결되어 있다
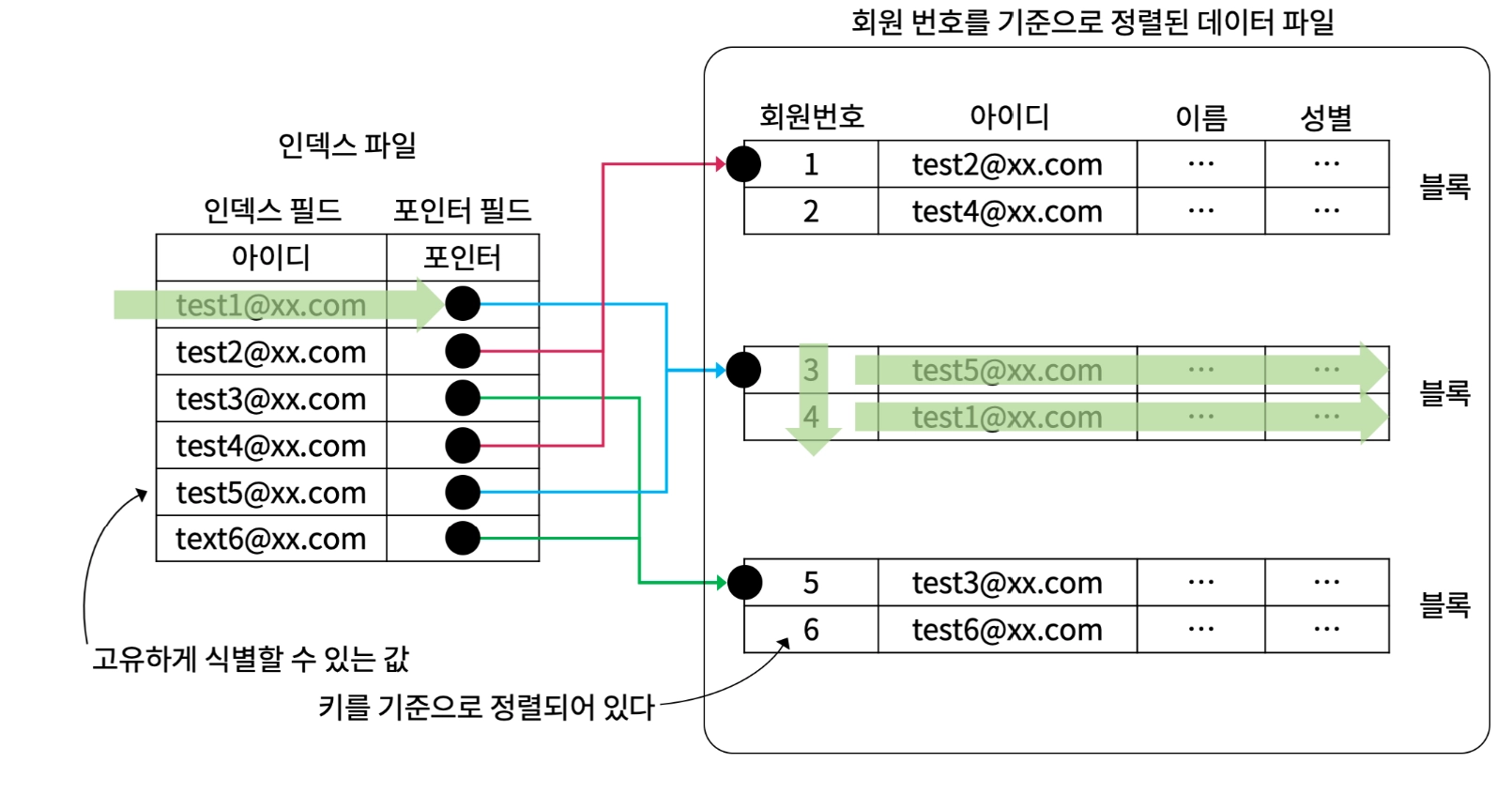
2. 보조 인덱스 Secondary Index
1.
인덱스 필드: 고유한 값을 가진 컬럼
2.
포인터 필드: 블록 또는 레코드의 위치값
•
보조인덱스는 기본인덱스보다 엔트리들의 개수가 많기 때문에 저장공간과 탐색 시간이 더 많이 소요된다.
•
기본 인덱스를 보조하기 위해 사용된다
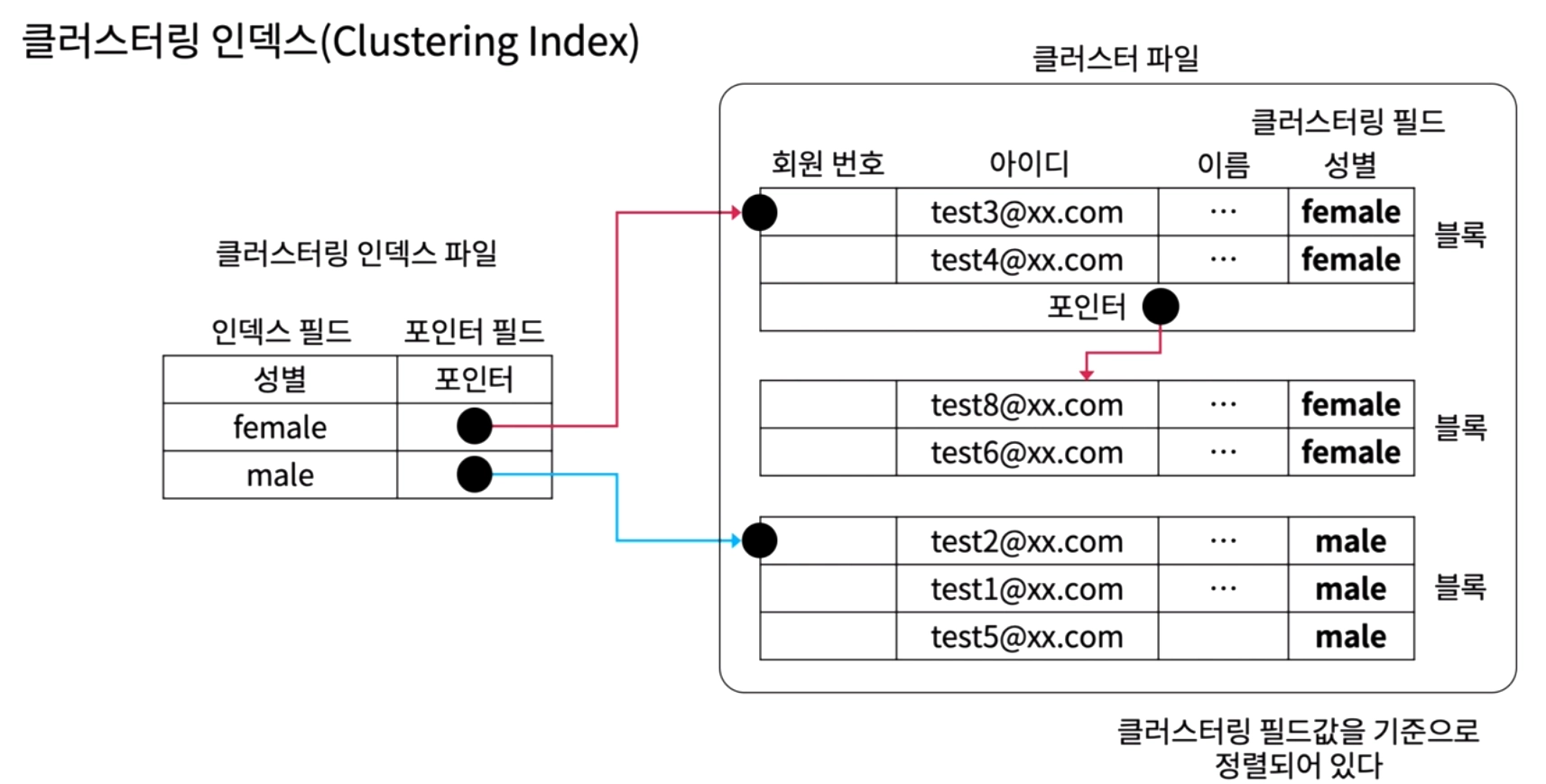
3. 클러스터링 인덱스 Clustering Index
1.
인덱스 필드: 중복되는 값을 가지는 커럼
2.
블록 포인터
•
인덱스 필드로 정렬되어 있다
•
블록에는 필드값이 동일한 레코드끼리 밀집되어 있다
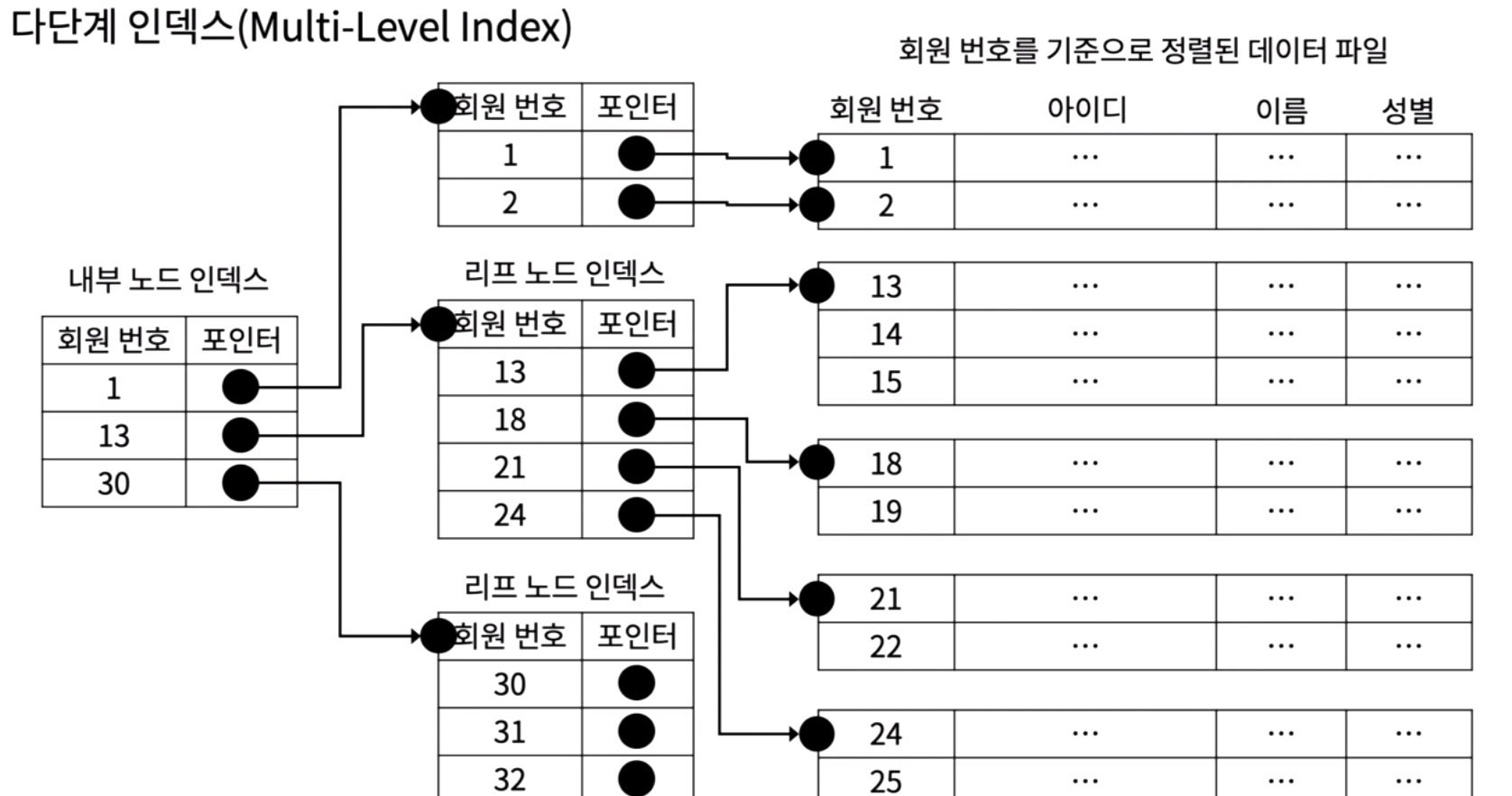
4. 다다계 인덱스 Multi-level Index
•
인덱스가 인덱스를 가리키는 (두단계 이상) 계층형 구조
•
덱스인 리프 노드 인덱스가 레코드의 위치를 저장하는 블록 포인터를 가지고 있습니다.
5. 해시 인덱스 Hash Index
•
해시 테이블:
◦
레크드의 키를 해쉬값으로 변환하고, 해쉬값에 해당하는 버킷에 레코드의 키와 블록 주소값을 저장
