
스프링부트 기반 프로젝트(게시판API 만들기)
오늘 배운 부분
DB 데이터 조회하고 웹브라우저에서 확인하기
•
이전 실습 > 복습
예상 결과물
 데이터 조회 흐름
데이터 조회 흐름
check
DB 접근은 빌드한 JPA을 사용하여 Repository의 메소드를 기반으로 검색한다.
JPA란?
Java Persistence API, 자바 진영의 ORM 기술 표준이다.
ORM이란?
직접 SQL을 작성하지 않고도 객체지향 방식으로 DB에 접근하는 기술이다.
데이터 조회 흐름
•
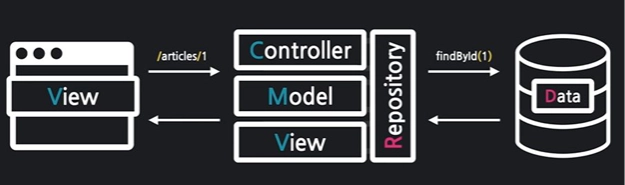
사용자가 서버에 데이터를 요청한다. (ID = 1인entity의 데이터)
•
요청을 Controller가 받고, 그 url에서 찾으려는 정보를 Repository에게 전달한다
•
Repository의 메소드로 DB에 전달하면 DB는 정보를 찾아 Entity를 반환
•
반환된 Entity는 model을 통해 view 템플릿으로 변환
•
최종 view는 클라이언트에게 결과값을 반환
URL 조회
check
•
JPA의 메소드인 findById()의 반환형은 Optional<T> 이다.
조회하려는 값이 존재할 수도, 존재하지 않을 수도 있어서 null에 의한 오류를 최소화 하기 위해 리턴으로 Optional<T>를 받는다.
GeneratedValue 전략
@GeneratedValue은 Article의 기본키를 자동으로 생성하는 전략이다.
DB로 차이점 확인하기
구현
Controller 코드 추가
@Controller
@RequestMapping("/articles")
@Slf4j
public class ArticleController {
// spring이 articleRepository구현체를 DI한다.
private final ArticleRepository articleRepository;
public ArticleController(ArticleRepository articleRepository) {
this.articleRepository = articleRepository;
}
...
// 1. article/{id}을 입력하면 {id}의 데이터 가져오기
@GetMapping("/{id}")
public String getArticle(@PathVariable Long id, Model model){
Optional<Article> optArticle = articleRepository.findById(id);
if(!optArticle.isEmpty()){
// 2. 해당 id의 article이 존재하면 데이터를 모델에 등록
model.addAttribute("article", optArticle.get());
return "show"; // 3. show.mustache 뷰 페이지를 보여준다
}else {
return "error"; // 4. error.mustache 뷰 페이지를 보여준다
}
}
Java
복사
•
findById()
// Repository의 findById()를 사용해 id로 article을 검색한다.
Optional<Article> optArticle = articleRepository.findById(id);
Java
복사
JPA 구현
환경 설정
entity
dto
repository
View 페이지 생성
•
templates
layout
new.mustache
error.mustache
show.mustache
전체 조회
check
•
Url조회(개별 조회)와 다른 점은 개별 조회는 Entity로만 반환했지만, 전체 조회는 List형태의 Entity로 반환한다.
구현
Controller 추가
@GetMapping("/list") //findAll 사용
public String list(Model model){
List<Article> articles = articleRepository.findAll();
model.addAttribute("articles", articles);
return "list";
}
@GetMapping("")
public String index() {
// "articles/"일 때도 list페이지로 보이도록 redirect
return "redirect:/articles/list";
}
Java
복사
•
findAll()
// Repository의 findAll()를 사용해 전체를 article을 조회하고 List에 담는다
List<Article> articles = articleRepository.findAll();
Java
복사
전체 조회 뷰페이지 작성
list.mustache 생성
{{>layouts/header}}
<h5>이 페이지는 리스트 페이지 입니다.</h5>
<table class="table">
<thread>
<tr>
<th scope="col">Id</th>
<th scope="col">Title</th>
<th scope="col">Content</th>
</tr>
</thread>
<tbody class="table-group-divider">
{{#articles}}
<tr>
<th>{{id}}</th>
<th><a href="/articles/{{id}}">{{title}}</a></th><br>
<th>{{content}}</th>
</tr>
{{/articles}}
</tbody>
</table>
<a href="/articles/new">생성</a>
{{>layouts/footer}}
Java
복사
BootStrap에서 Table을 적용했다.
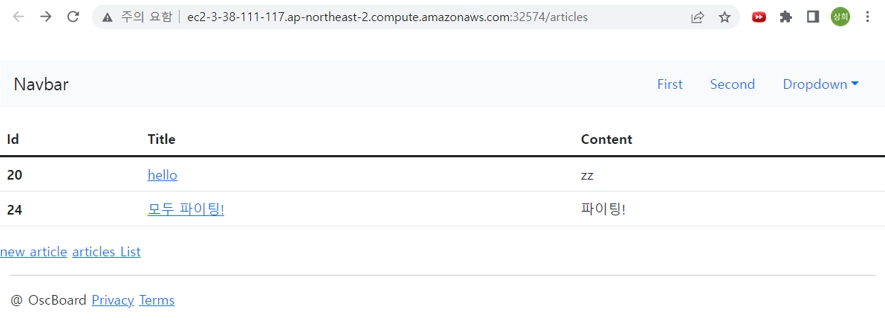
결과물
list
생성 click
list에서 title click
주의할 점
application.yml에서 ddl-auto 옵션 설정
jpa:
show-sql: true
# hibernate 설정
database-platform: org.hibernate.dialect.MySQL8Dialect
database: mysql
hibernate.ddl-auto: update
XML
복사
•
운영 장비에서는 절대 crate, create-drop, update 사용하면 안된다.
◦
개발 초기 단계는 create 또는 update
◦
테스트 서버는 update 또는 validate
◦
스테이징과 운영 서버는 validate 또는 none
•
옵션 목록
create
옵션은 로컬환경에서만 사용해야 된다는 것이다.
create 옵션은 해당하는 테이블이 있으면 DROP하고 새로 만들어 버리기 때문에 이전 데이터가 날라가버리는 문제점이 발생한다.
create-drop
create와 같으나 종료시점에 테이블 DROP된다.
update
시작하면서 도메인 객체 구성과 DB의 스키마를 비교해 필요한 테이블이나 칼럼이 없을 때 도메인 객체에 맞춰 DB 스키마를 변경한다. 데이터나 스키마를 지우지는 않는다. → 그냥 테이블이나 칼럼이 없으면 만드는 정도이지만 실제 배포할 때는 문제가 될 수 있다.
validate
처음에 도메인 객체 구성과 DB 스키마가 같은지 확인만 할 뿐 DB 스키마에 전혀 손대지 않는다. SessionFactory 시작 시 확인을 해서 문제가 있으면 예외를 토해내고 죽는다.
그 외
