
목차
 알고리즘
알고리즘
Hash Table
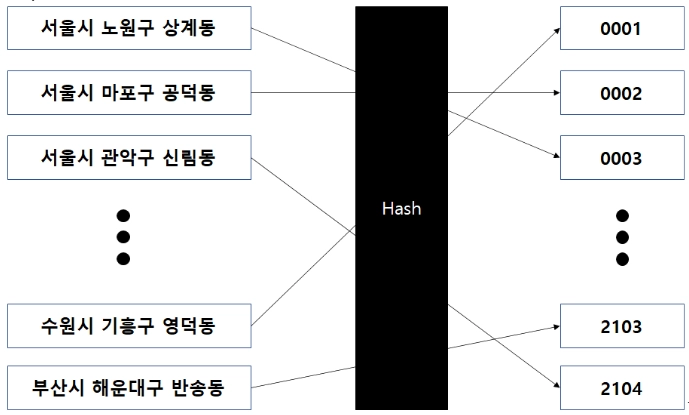
Hash Table의 개념
•
key값을 hash함수에 넣어 index로 반환받은 다음 value를 해당 index에 대입하는 자료구조이다.
•
Hash의 검색 속도는 O(1)이다. hash함수에서 리턴된 index를 가지고 검색하기 때문이다.
Hash 메소드의 구현
Hash 메소드 구현 코드
Hash insert 메소드 구현
Hash insert 메소드 구현 코드
Hash search 메소드 구현
Hash search 메소드 구현 코드
HashTableTest
test 코드
java_DB 연동하기
1. 프로젝트 빌드하기
Build의 개념
소스코드 파일을 실행가능한 소프트웨어 산출물로 만드는 일련의 과정을 말한다.
빌드의 단계 중 컴파일이 포함이 되어 있는데 컴파일은 빌드의 부분집합이라 할 수 있다.
빌드 과정을 도와주는 도구를 빌드 툴이라 한다.
빌드 툴의 기능은 전처리, 컴파일, 패키징, 테스팅, 배포가 있다.
gradle을 사용하는 이유


gradle은 가장 최근에 나온 자바 빌드 도구로 그루비 문법을 사용한다. build.gradle에 스크립트를 작성하며, 대규모 프로젝트에서 복잡해지는 경향이 있는 xml기반 스크립트에 비해 관리가 편하다는 장점이 있다.
프로젝트 빌드 과정
과정
2. JDBC를 활용한 insert와 select
JDBC란?


DB에 접근할 수 있도록 JAVA에서 제공하는 API
JDBC 드라이버란?
•
DBMS와 통신을 담당하는 자바 클래스
•
DBMS 별로 알맞은 JDBC 드라이버 필요
JDBC 문법 Statement 와 PreparedStatement 차이점

•
Statement
◦
Statement 객체는 Statement 인터페이스를 구현한 객체를 Connection 클래스의 createStatement() 메소드를 호출함으로써 얻어진다.
◦
Statement는 정적인 쿼리문을 처리할 수 있다.
즉, 쿼리문에 값이 미리 입력되어있어야한다.
•
PreparedStatement
◦
PreparedStatement 객체는 Connection 객체의 preparedStatement()메소드를 사용해서 생성한다. 이 메소드는 인수로 SQL문을 담은 String 객체가 필요하다.
◦
SQL문장이 미리 컴파일되고, 실행 시간동안 인수 값을 위한 공간을 확보할 수 있다는 점에서 Statement 객체와 다르다.
◦
Statement 객체의 SQL은 실행될 때, 매번 서버에서 분석해야하는 반면 PreparedStatement 객체는 한 번 분석되면 재사용이 용이하다.
◦
각각 인수에 대해 위치홀더(placeholder)를 사용하여 SQL문장을 정의할 수 있게 해준다. 위치 홀더는 ? 로 표현된다.
mysql과 자바 연동
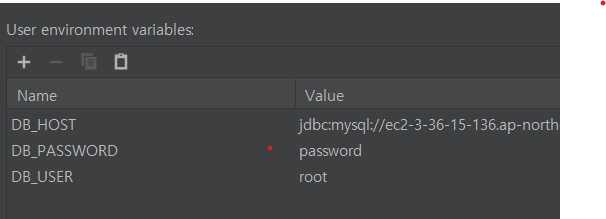
Map<String, String> env = System.getenv();
Connection connection = DriverManager.getConnection(
env.get("DB_HOST"), env.get("DB_USER"), env.get("DB_PASSWORD")
);
//DB_HOST : jdbc:mysql://url
//DB_USER : id
//DB_PASSWORD : DB의 패스워드
Java
복사
•
DriverManager를 통해서 db 연동 시 환경변수를 통해서 db의 url, id, password를 넣어줘야 한다.
•
이유는 git에 db의 url, password를 포함해서 코드를 올린 경우 다른 사람이 해킹을 해서 db에 해를 끼칠 수 있기 때문이다.
add, findById 메소드
add 메소드 코드
findById 메소드 코드
전체 코드
User 코드
UserDao 코드
UserDaoTest 코드
토비의 스프링 1장
1. 관심사의 분리
유튜브 강의
이전 코드의 문제점
💡 중복되는 부분이 많다. 만약 중복되는 내용에서 수정이 필요하다면
반복적인 수정 작업이 이루어진다.
Plain Text
복사
중복되는 부분을 method로 분리
// insert, select의 공통된 부분
Map<String,String> env = System.getenv();
Connection c = DriverManager. getConnection( env.get("DB_HOST"), env.get("DB_ID"), env.get("DB_PASSWORD"));
Java
복사
UserDao 메소드 리팩토링 코드
2. Abstract Class(추상클래스)
Abstarct Class란?
•
Abstract 메소드를 최소한 1개를 포함하고 있는 클래스
•
Abstract 클래스 자체 객체를 생성할 수 없고 구현 클래스를 만들어야 한다.
이전 코드의 문제점
💡 다른 db 서버에 users 테이블을 구현하고 UserDao의 기능을 사용하는 것을 원할때
UserDao의 소스코드를 공개해야한다.
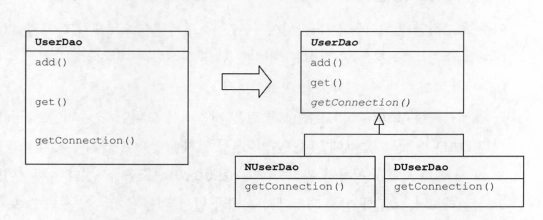
이를 해결하기 위해 Template Method Pattern으로 구현
* Template Method Pattern :
공통부분은 남기고 변화가 있는 부분을 abstract method로 만드는 것
Plain Text
복사
Template Method Pattern
템플릿 메소드 패턴
상속을 통해 슈퍼클래스의 기능을 확장할 때 사용하는 가장 대표적인 방법이다. 변하지 않는 기능은 슈퍼클래스에 만들어두고 자주 변경되며 확장할 기능은 서브클래스에서 만들도록 한다. 슈퍼클래스에서는 미리 추상 메소드 또는 오버라이드 가능한 메소드를 정의해두고, 이를 활용해 코드의 기본 알고리즘을 담고 있는 템플릿 메소드를 만든다. 슈퍼클래스에서 디폴트 기능을 정의해두거나 비워뒀다가 서브클래스에서 선택적으로 오버라이드할 수 있도록 만들어둔 메소드를 훅 메소드라고 한다. 서브클래스에서는 추상 메소드를 구현하거나, 훅 메소드를 오버라이드하는 방법을 이용해 기능의 일부를 확장한다.
Abstract 코드
Abstract를 상속받은 클래스 코드
3. Class로 분리
이전 코드의 문제점
💡 상속관계는 많은 한계점이 있다. 만약 UserDao를 상속받아야할 클래스가
다른 클래스를 먼저 상속받고 있다면 문제가 발생한다.
상속관계는 다중상속이 지원되지 않는다.
그래서 connection을 클래스로 분리하여 해결해 볼려고 한다.
Plain Text
복사
Connection 부분을 분리한 코드
4. Interface의 도입
이전 코드의 문제점
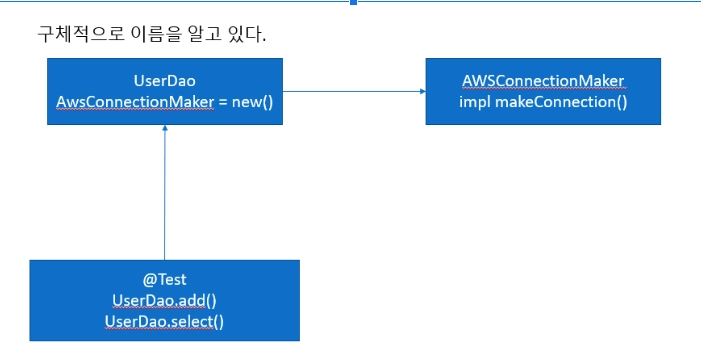
💡UserDao에서 jdbc와 특정 db와 연결된 AWSConnectionMaker의 객체를 사용하고 있다.
이는 jdbc와 다른 db와 연결할 때 클래스 생성, connection 객체 변경 등 수정해야할 부분이
많다. 이를 해결하고자 interface를 적용한다.
Java
복사
Interface 분리 적용
UserDao에서는 ConnectionMaker Interface를 의존하고 있기 때문에 ConnectionMaker의 구현체를 모두 사용할 수 있다.
ConnectionMaker를 interface로 적용한 코드
5. Factory 적용_(관계설정 책임의 분리)
이전 코드의 문제점
💡 UserDaoTest는 ConnectionMaker 구현 클래스를 객체로 생성하는 기능을 갖고 있다.
UserDaoTest는 UserDao의 기능이 잘 동작하는지 테스트를 위한 클래스이기때문에
UserDaoTest에 있는 ConnectionMaker Maker 구현 부분을 분리하는 것이 필요하다.
Plain Text
복사
UserDaoFactory
•
이 클래스의 역할은 객체의 생성 방법을 결정하고 그렇게 만들어진 객체를 돌려주는 것이다.
•
오브젝트를 생성하는 쪽과 생성된 오브젝트를 사용하는 쪽의 역할과 책임을 분리하는 목적으로 사용한다.
•
새로운 ConnectionMaker 구현 클래스가 필요하다면 DaoFactory를 수정해서 변경된 클래스를 생성해 설정해주도록 코드를 수정하면 된다.
•
핵심 코드인 UserDao는 변경 필요없이 안전하게 소스코드를 보존할 수 있다.
UserDaoFactory 코드
UserDaoFactory를 적용한 코드
지금까지의 코드구조분석
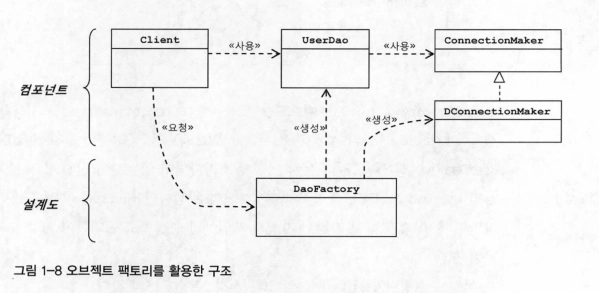
1.
Client는 Object를 사용하는 쪽을 Client라고 한다.
•
예제코드에서 UserDaoTest 코드가 클라이언트가 된다.
2.
UserDao는 ConnectionMaker에만 의존하고 있다.
3.
DaoFactory에는 UserDao와 ConnectionMaker 구현체를 조립한다.
4.
Client에서는 DaoFactory에 요청해서 userDao를 받아온다.
6. Spring
Spring이란?


java의 웹프레임워크로 java로 다양한 어플리케이션을 만들기 위한 프로그래밍 틀이라 할 수 있다.
프로젝트를 진행하면 중복되는 코드가 있기 마련이다. Spring은 이런 중복코드의 사용률을 줄여주고, 비즈니스 로직을 더 간단하게 만들어 줄 수 있다.
Frame Work란?
프레임워크는 목적을 달성하기 위해 복잡하게 얽혀 있는 문제를 해결하기 위한 구조이자 약속이다. 소프트웨어 개발에 있어서 하나의 뼈대 역할을 한다.
간단하게 말하자면 프레임 워크는 자주 사용할만한 기능을 한데 모아 놓은 유틸(클래스)들의 모음 이라고 정의할 수 있다.
Spring 실습 준비
실습 준비 과정
Spring 용어 정리
•
Bean
빈 또는 빈 오프젝트는 스프링이 IoC 방식으로 관리하는 오브젝트라는 뜻이다. 주의할 점은 스프링을 사용하는 애플리케이션에서 만들어지는 모든 오브젝트가 다 빈은 아닌 사실이다. 그 중에서 스프링이 직접 그 생성과 제어를 담당하는 오브젝트만을 빈이라고 부른다.
•
Bean Factory
스프링의 IoC를 담당하는 핵심 컨테이너를 가리킨다. 빈을 등록하고, 생성하고, 조회하고 돌려주고, 그 외에 부가적인 빈을 관리하는 기능을 담당한다. 보통 이 빈 팩토리를 바로 사용하진 않고, 이를 확장한 애플리케이션 컨텍스트를 이용한다. BeanFactory라고 붙여쓰면 빈 팩토리가 구현하고 있는 가장 기본적인 인터페이스의 이름이 된다. 이 인터페이스에 getBean()과 같은 메소드가 정의되어 있다.
•
ApplicationContext
빈 팩토리를 확장한 IoC 컨테이너다. 빈을 등록하고 관리하는 기본적인 기능은 빈 팩토리와 동일하다. 여기에 스프링이 제공하는 각종 부가 서비스를 추가로 제공한다. 빈 팩토리라고 부를 때는 주로 빈의 생성과 제어의 관점에서 이야기하는 것이고, 애플리케이션 컨텍스트라고 할 때는 스프링이 제공하는 애플리케이션 지원 기능을 모두 포함해서 이야기하는 것이다. 스프링에서는 애플리케이션 컨텍스트라는 용어를 빈 팩토리보다 더 많이 사용한다. ApplicationContext라고 적으면 애플리케이션 컨텍스트가 구현해야 하는 기본 인터페이스를 가리키는 것이기도 하다. ApplicationContext는 BeanFactory를 상속한다.
•
Container
IoC 방식으로 빈을 관리한다는 의미에서 애플리케이션 컨텍스트나 빈 패토리를 컨테이너 또는 IoC 컨테이너라고도 한다. 후자는 주로 빈 팩토리의 관점에서 이야기하는 것이고, 그냥 컨테이너 또는 스프링 컨테이너라고 할 때는 애플리케이션 컨텍스트를 가리키는 것이라고 보면 된다. 컨테이너라는 말 자체가 IoC의 개념을 담고 있기 때문에 이름이 긴 애플리케이션 컨텍스트 대신 스프링 컨테이너라고 부르는 걸 선호하는 사람들도 있다. 또 컨테이너라는 말은 애플리케이션 컨텍스트보다 추상적인 표현이기도 하다. 애플리케이션 컨텍스트는 그 자체로 ApplicationContext 인터페이스를 구현한 오브젝트를 가리키기도 하는데, 애플리케이션 컨텍스트 오브젝트는 하나의 애플리케이션에서 보통 여러 개가 만들어져 사용된다. 이를 통틀어서 스프링 컨테이너라고 부를 수 있다. 때로는 컨테이너라는 말을 떼고 스프링이라고 부를 때도, 바로 이 스프링 컨테이너를 가리키는 것일 수도 있다. 예를 들어 “스프링에 빈을 등록하고”라는 식의 말하는 경우에 스프링이라는 말은 스프링 컨테이너 또는 애플리케이션 컨텍스트를 가리키는 말이다.
스프링의 주요 어노테이션
•
@Configuration
해당 어노테이션을 단 클래스는 빈 설정을 담당하는 클래스가 된다. 이 클래스 안에서 @Bean 어노테이션이 동봉된 메소드를 선언하면, 그 메소드를 통해 스프링을 정의한다.
•
@ContextConfiguration
자동으로 만들어줄 ApplicationContext의 설정 파일 위치를 지정한 것이다.
우리는 테스트 코드에서 @ContextConfiguration(classes = UserDaoFactory.class)의 형식으로 작성
이로써, ApplicationContext 즉, 스프링 컨테이너의 설정 파일의 위치를 지정해준 것이다.
•
@Bean
빈을 등록하는 어노테이션
애플리케이션 컨텍스트의 동작방식p.101
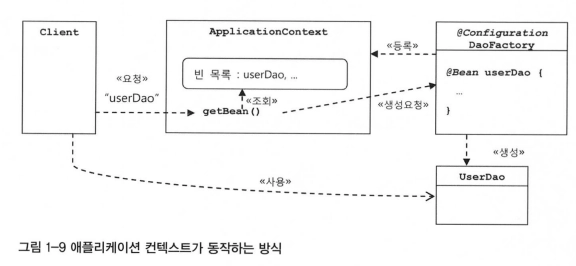
DaoFactory가 UserDao를 비롯한 DAO 오브젝트를 생성하고 DB 생성 토브젝트와 관계를 맺어주는 제한적인 역할을 하는데 반해, 애플리케이션 컨텍스트는 애플리케이션에서 IoC를 적용해서 관리할 모든 오브젝트에 대한 생성과 관계설정을 담당한다. 대신 ApplicationContext에는 DaoFactory와 달리 직접 오브젝트를 생성하고 관계를 맺어주는 코드가 없고, 그런 생성정보와 연관관계 정보를 별도의 설정정보를 통해 얻는다. 때로는 외부의 오브젝트 팩토리에 그 작업을 위임하고 그 결과를 가져다가 사용하기도 한다.
@Configuration이 붙은 DaoFactory는 이 애플리케이션 컨텍스트가 활용하는 IoC 설정정보다, 내부적으로는 애플리케이션 컨텍스트가 DaoFactory의 userDao() 메소드를 호출해서 오브젝트를 가져온 것을 클라이언트가 getBean()으로 요청할 때 전달해준다. 그림 1-9는 이 애플리케이션 컨텍스트가 사용되는 방식을 보여준다.
애플리케이션 컨텍스트는 DaoFactory 클래스를 설정정보로 등록해두고 @Bean이 붙은 메소드의 이름을 가져와 빈 목록을 만들어둔다. 클라이언트가 애플리케이션 컨텍스트의 getBean() 메소드를 호출하면 자신의 빈 목록에서 요청한 이름이 있는지 찾고, 있다면 빈을 생성하는 메소드를 호출해서 오브젝트를 생성시킨 후 클라이언트에 돌려준다.
애플리케이션 컨텍스트를 활용하는 이유p.102
•
클라이언트는 구체적인 팩토리 클래스를 알 필요가 없다.
◦
클라이언트가 필요한 오브젝트를 가져오려면 어떤 팩토리 클래스를 사용해야 할지 알아야 하고, 필요할 때마다 팩토리 오브젝을 생성해야 하는 번거로움이 있다.
◦
애플리케이션 컨텍스트를 사용하면 오브젝트 팩토리가 아무리 많아져도 이를 알아야하거나 직접 사용할 필요가 없다.
•
애플리케이션 컨텍스트는 종합 IoC 서비스를 제공해준다.
◦
애플리케이션 컨텍스트의 역할은 관계설정만이 아닌 자동생성, 오브젝트에 대한 후처리, 정보의 조합, 설정의 방식의 다변화, 인터셉팅 등 오브젝트를 효과적으로 활용할 수 있는 다양한 기능을 제공한다.
•
애플리케이션 컨텍스트는 빈을 검색하는 다양한 방법을 제공한다.
제어의 역전(IoC)
UserDao에서 ConnectionMaker의 구현 클래스를 결정하고, 오브젝트를 만드는 젝어권은 UserDao에게 있었다.
하지만, UserDaoFactory가 구현된 이후로 오브젝트를 만드는 제어권은 UserDaoFactory에게 있다.
이로써 UserDao는 수동적인 존재가 되어버리고, UserDaoFactory가 객체를 생성과 관계를 관리해주는 것, 이것이 제어의 역전이다.
•
제어의 역전은 오브젝트가 자신이 사용할 오브젝트를 스스로 선택, 생성하지 않는다.
•
모든 제어 권한을 자신이 아닌 다른 대상에게 위임
•
application context라고 하는 IoC 컨테이너를 통해 IoC를 관리한다.
•
컨테이너는 특정 객체의 생성과 관리를 담당하고, 객체 운용에 필요한 다양한 기능을 제공한다.
•
스프링은 IoC를 극한까지 적용하는 프레임 워크이다.
DI(Dependency Injection)
•
의존관계 주입, 의존관계 설정이라는 의미이다.
•
스프링 IoC 기능의 대표적인 동작원리다.
•
오브젝트 레퍼런스를 외부로부터 제공받고 이를 통해 다른 오브젝트와 의존관계가 만들어진다.
◦
의존관계 : 한쪽의 변화가 다른 쪽에 영향을 주는 것을 말한다.
◦
예를 들면 UserDao는 ConnectionMaker를 의존하고 있다. ConnectionMaker의 구현 객체가 변경되면 UserDao에도 영향을 끼친다.
싱글톤
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton() {
// 생성자는 외부에서 호출못하게 private 으로 지정해야 한다.
}
public static Singleton getInstance() {
return instance;
}
public void say() {
System.out.println("hi, there");
}
}
Java
복사
•
객체의 인스턴스가 오직 1개만 생성되는 패턴을 의미한다.
•
한번의 new 연산자를 통해서 고정된 메모리 영역을 사용하기 때문에 추후 해당 객체에 접근할 때 메모리 낭비를 방지할 수 있다.
•
이미 생성된 인스턴스를 활용하기 때문에 속도 측면에서도 이점이 있다.
•
싱글톤에 대한 정리글 :


싱글톤(ApplicationContext)를 사용해야 하는 이유
GC(Garbage Collection)을 줄이기 위해서이다.
클라이언트 요청 한번에 5개의 오브젝트가 새로 만들어지고 초당 500개의 요청이 들어오면, 초당 2500개의 오브젝트가 생성된다. 이렇게 오브젝트가 시간이 지나면서 기하급수적으로 늘어나게 된다면 서버는 다운된다.
JUnit의 주요 어노테이션
•
@ExtendWith(SpringExtension.class)
Junit에서 Spring ApplicationContext를 사용할 수 있게 해주는 기능
•
@ContextConfiguration
Junit test코드를 실행 할 때 applicationContext에 들어갈 설정 정보를 불러오게 해주는 기능
Spring을 적용한 UserDaoFactory, UserDaoTest
UserDaoFactory 코드
UserDaoTest 코드
토비의 스프링 2장
1. Test
Test를 만들 때 중요한 점
언제 실행해도 동일한 결과가 나오게끔 테스트를 구성해야 한다.
Test를 실행시킬 때마다 똑같은 결과가 나올 수 있도록 셋팅을 해주어야 한다.
deleteAll()
•
DELETE FROM users를 실행하는 메소드
•
users 테이블에 존재하는 모든 레코드 수 삭제
deleteAll 코드
getCount()
•
SELECT COUNT(users) FROM users 를 실행하는 메소드
•
users 테이블에 존재하는 모든 레코드의 수를 반환
getCount 코드
UserDaoTest 리팩토링
UserDaoTest 클래스 코드
•
@BeforEach의 적용
◦
각 @Test 메소드가 실행 될때마다 실행되는 코드가 있다. 그 부분을 Junit에서 공통화 시킬 수 있게 제공하는 기능이 BeforeEach이다.
@BeforEach 적용 코드
데이터가 없을 때 ResultSet이 빈 경우
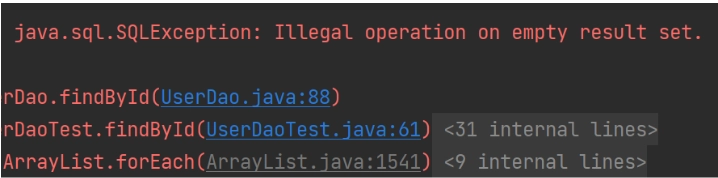
•
findById메소드에서 users에 없는 레코드를 반환받는 시도를 할 때 위와 같은 exception이 생긴다.
•
EmptyResultDataAccessException(1) 위 경우 에러처리를 한다.
findById 리팩토링 코드
findById 리팩토링 테스트 코드
JUnit의 작동 방식
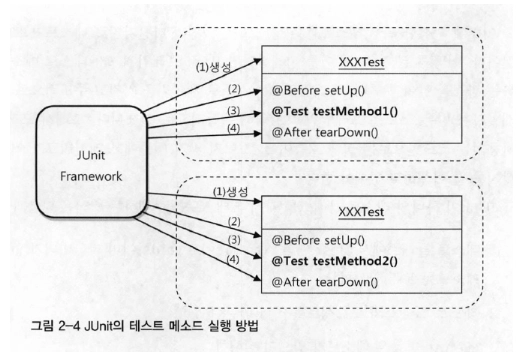
1.
테스트 클래스에서 @Test가 붙은 public이고 void형이며 파라미터가 없는 테스트 메소드를 모두 찾는다.
•
public은 생략해도 된다.(Junit 5)
2.
테스트 클래스의 오브젝트를 하나 만든다,
3.
@BeforeEach가 붙은 메소드 실행
4.
@Test가 붙은 메소드를 하나 호출하고 테스트 결과를 저장한다.
5.
@AfterEach가 붙은 메소드 실행
6.
나머지 남은 테스트에 대해 2~5번을 반복
7.
모든 테스트 결과를 종합해서 돌려준다.
Junit5에서 테스트 실행할 때 마다 오브젝트를 생성하는 이유
•
각 테스트가 서로 영향을 주지 않고 독립적으로 실행됨을 확실히 보장해주기 위해 매번 새로운 오브젝트를 만든다.
•
테스트 클래스는 인스턴스 변수를 매번 새로 생성해주기 때문에, 독립적인 실행을 확실하게 보장한다.
•
따라서, 각 테스트 메소드끼리는 의존이 전혀 없으므로, 테스트 메소드 실행에 대한 순서가 보장되지 않는다.
•
Test Method순서 정하기 : https://psawesome.tistory.com/32
ApplicationContext Singleton

•
@Autowired를 이용해 Container에서 가져오게 하여 new를 한번만 하도록 한다.
•
@Autowired
◦
필요한 의존 객체의 “타입"에 해당하는 빈을 ApplicationContext 에서 찾아 주입한다.
◦
필드 주입, 생성자 주입, 설정자 주입의 3가지로 DI가 가능하다.
◦
우리가 작성한 방식은 필드 주입 방식이다.
◦
즉, 이 어노테이션을 통해 AppplicationContext라는 빈 객체를 스프링 컨테이너가 알아서 자동으로 주입해주는 것이다.
ApplicationContext에서 Bean을 가지고 올 때 Spring이 검색하는 방법
•
getBean()을 통해 스프링에 등록된 빈을 조회할 수 있다.
•
빈의 이름은 설정 클래스에서 @Bean 어노테이션을 통해 빈을 생성하는 각 메소드의 이름으로 지정된다.
토비의 스프링 3장
1. 예외처리
예외처리가 없을 때 문제점
public void deleteAll() throws SQLException {
Connection c = connectionMaker.connectionMaker();
PreparedStatement p = c.prepareStatement(
"DELETE FROM users;"
);
p.executeUpdate();
p.close();
c.close();
}
Java
복사

•
SQLException 발생시 close()가 실행되지 않는 문제가 발생한다.
•
리소스의 반환이 이루어지지 않아 서버가 다운된다.
리소스 반환을 위한 예외처리 리팩토링
•
에러가 발생하든 발생하지 않든, 커넥션과 PreparedStatement, ResultSet과 같은 클래스는 풀에 있는 위에서 언급한 것과 같이 정해진 풀 안에 제한된 리소스를 만들어두고, 필요할 때 할당하고 반환하면 다시 풀에 넣는 방식으로 사용한다.
•
만약 makeConnection()에서 Db 커넥션을 가져오다가 일시적인 db 서버 문제나, 네트워크 문제 때문에 예외가 발생했다면, PreparedStatement와 커넥션 오브젝트는 아직 모두 null 상태이다.
◦
null 상태의 변수에 close() 메소드를 호출하면 NPE가 발생할 테니 이럴 땐 close() 메소드를 호출하면 안된다.
•
또 다른 상황으로, PreparedStatement를 생성하다가 예외가 발생했다면, 그 때는 c 변수가 커넥션 객체를 갖고 있는 상태이므로 c는 close() 호출이 가능한 반면 pstmt는 아니다.
•
이 말의 요지는 어느 시점에서 예외가 발생했는지에 따라서 close()를 사용할 수 있는 변수가 달라질 수 있기 때문에 finally에서는 반드시 c와 pstmt가 null이 아닌지 먼저 확인한 후에 close() 메소드를 호출해야 한다.
예외처리 리팩토링 코드
2. DataSource 인터페이스 적용
DataSource의 개념


•
자바 프로그램에서 connection 객체를 얻는 것은 시간이 걸린다.
•
일정량의 connection 객체를 미리 만들어 저장하고, 요청 시 꺼내 사용한다.
•
위와 같은 과정으로 구현하면 속도와 퍼포먼스가 좋아진다.
•
connection pool을 관리하고, connection 객체를 pool에서 꺼내 사용했다 반납하는 이러한 과정을 DataSource가 한다.
DataSource를 활용한 UserDaoFactory 리팩토링
UserDaoFctory 리팩토링 코드
DI할 때 final을 사용하는 이유
•
final이란 무엇인가?
◦
한번 초기화 되면 바꿀 수 없는 것
◦
private final DataSource dataSource;
◦
final로 선언한 변수는 재할당을 할 수 없다.
•
final을 사용할 때 이점
1.
변화를 고려하지 않아도 된다.
2.
변경을 고려하지 않기 때문에 변경에 필요한 메모리 할당이 필요없다. - memory를 절약
3.
Di하고나서 DataSource가 바뀌는 경우 - 무슨일이 일어날지 예측이 안된다.
•
final을 쓰는 이유
1.
Spring에서 DI되었다면 이미 Factory에서 조립이 끝난 상태이므로 변화하지 않는게 좋다.
2.
변화하지 않는게 좋으므로 final로 쓰는게 좋다. 왜냐하면 메모리 사용에 유리하고 신뢰성 있기 때문
3.
이후 SpringBoot에서 @Autowired하는 부분이 final로 대체하는 것을 권장하게 바뀜.
3. 익명 클래스 도입
deleteAll, add 메소드에서 익명 클래스를 사용하는 이유
StatementStrategy Interface 구현체인 DeleteAllStrategy와, AddStrategy를 쓰는 곳은 UserDao의 각 deleteAll, add 메소드 한곳이므로 굳이 class를 새로 만들 필요가 없다.
deleteAll, add 메소드 리팩토링
jdbcContextWithStatementStrategy 를 사용할 때는 StatementStrategy 인터페이스 구현체를 넘겨주어야 한다.
deleteAll 메소드 코드
add 메소드 코드
4. JdbcContext로 분리
UserDao의 jdbcContextWithStatementStrategy를 클래스로 분리하는 이유
jdbcContextWithStatementStrategy는 다른 Dao에서도 사용할 수 있다. (ex. HospitalDao) 그래서 다른 Dao에서도 쓰기 위해 UserDao에서 분리 한다.
JdbcContext분리
JdbcContext 클래스 코드
UserDao에 JdbcContext를 의존하게 리팩토링
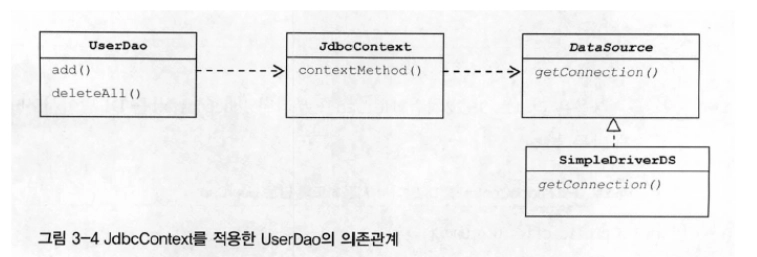
의존관계가 UserDao가 JdbcContext의존하게 변경됨
new JdbcContext(dataSource);
책에서는 위 구간을 set을 활용해 구현했지만 이 방식은 xml 설정 방식이다.
지금은 xml 설정 방식을 잘 사용하지 않기 때문에 생성자로 구현한다.
UserDao 리팩토링 코드
지금까지 적용했던 Strategy 패턴들
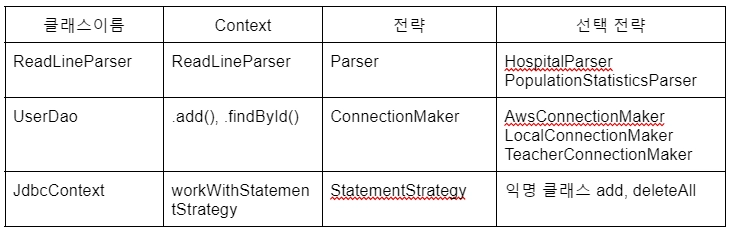
JdbcContext와 DataSource의 관계 설정을 Constructor에서 한 이유


5. Template Callback 적용
callback
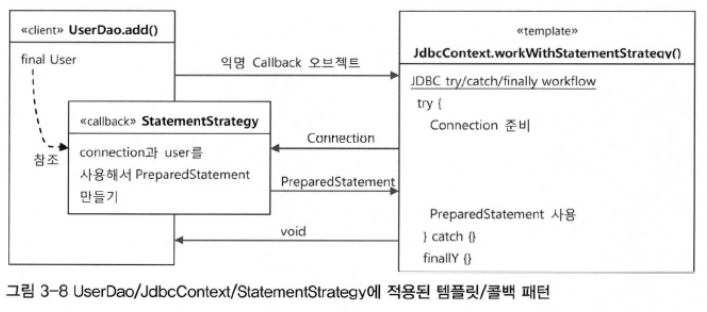
add함수를 호출하면 jdbcContext.workWithStatementStrategy함수가 호출되고
workWithStatementStrategy 함수는 StatementStrategy 함수를 호출 그리고 PreparedStatement를 반환받고 돌아오고 workeWithStatementStrategy함수는 종료 다시 add함수로 돌아온다.
executeSql 메소드
executeSql 메소드 코드
deleteAll 메소드 코드
6. Jdbc Template 적용
JDBC란?


DB에 접근할 수있도록 Java에서 제공하는 API
Plain JDBC의 문제점
•
쿼리를 실행하기 전과 후에 많은 코드를 작성해야한다. (연결생성, 명령문 etc..)
•
예외처리코드와 트랜잭션 처리등에 시간과 자원이 소모된다.
◦
jdbc에서 발생하는 에러는 Runtime Exception이다. 따라서 모두 예외처리를 해줘야한다.
•
이러한 문제점을 보완하기 위해 spring JDBC이다.
Spring JDBC란?
JDBC의 단점을 보완하여 더 편리한 기능을 제공
Spring JDBC가 하는 일
•
Connection 열기와 닫기
•
Statement 준비와 닫기
•
Statement 실행
•
ResultSet Loop처리
•
Exception 처리와 반환
•
Transaction 처리
Spring JDBC에서 개발자가 할 일
•
datasource 설정
•
sql문 작성
•
결과 처리
JDBC Template이란?
Spring JDBC 접근 방법 중 하나로, 내부적으로 Plain JDBC API를 사용하지만 위와 같은 문제점을 해결한 Spring에서 제공하는 클래스
JDBC Templete이 제공하는 기능
•
실행 : Insert나 Update같이 DB의 데이터에 변경이 일어나는 쿼리를 수행하는 작업
•
조회 : Select를 이용해 데이터를 조회하는 작업
•
배치 : 여러 개의 쿼리를 한 번에 수행해야 하는 작업
•
jdbc template을 사용하면 커넥션 연결/종료와같은 세부적인 작업을 개발자가 직접 처리하지 않아도 되게된다.
JPA란?
JDBC Template보다 더 추상적인 클래스
JdbcTemplate 활용
UserDao 리팩토링 코드
UserDaoTest 코드
