

.png&blockId=3197e115-ee0d-4d9c-9f5d-4b57cb28634e)
1. 개요
•
우리는 이전까지 인덱스의 구성에 따라 탐색속도가 달라지는 것을 확인하였고 인덱스를 어떻게 설계하느냐는 효율측면에서 매우 중요하다는 것을 알 수 있다.
•
현업에서는 개발 도중에 다양한 요구사항이 발생하기 때문에 설계 시 어떻게 질의를 할 것인지 예측하기 여럽다. 때문에 질의 설계 완료 후, 인덱스 도입을 고민하는 것이 좋다.
옵티마이저 개념
•
사용자로부터 질의를 전달받았을 때 가장 효율적인 방법으로 질의를 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 엔진이다.
•
쉽게말해, 쿼리문 실행전 어떻게 실행할건지 실행계획을 세우는 것이다.
•
중요한 점은 <인덱스 존재유무>와 <어떤 칼럼의 값을 가져오는지>에 따라 실행계획이 달라진다.
예시로 사용할 table
CREATE TABLE MEMBER (
M_ID INT UNSIGNED NOT NULL PRIMARY KEY, // 클러스터 인덱스 키
M_MEMBER_ID VARCHAR(32) NOT NULL UNIQUE, // 보조 인덱스 키 (유니크)
M_NAME VARCHAR(32) NOT NULL,
M_GENDER VARCHAR(6) NULL DEFAULT 'female',
M_BIRTH CHAR(6) NULL,
M_CREATED_DATE DATE NULL,
INDEX `gender_name` (M_GENDER, M_NAME) // 보조 인덱스 키 (칼럼인덱스)
);
SQL
복사
질의 실행 계획 확인하기 EXPLAIN
// EXPLAIN 문법
EXPLAIN [format=tree|json] [SELECT 구문]
// 예시 : ID가 2인 행의 모든 칼럼을 가져오는 구문의 실행계획 확인
EXPLAIN SELECT * FROM MEMBER WHERE ID = 2;
/ 테이블명
Java
복사
칼럼 별 의미 설명
이제 이 EXPLAIN 질의의 결과를 통해 <인덱스 존재유무>와 <어떤 칼럼의 값을 가져오는지>에 따라, 각 실행계획이 어떤식으로 탐색을 하게 되는지 살펴보도록 하자.
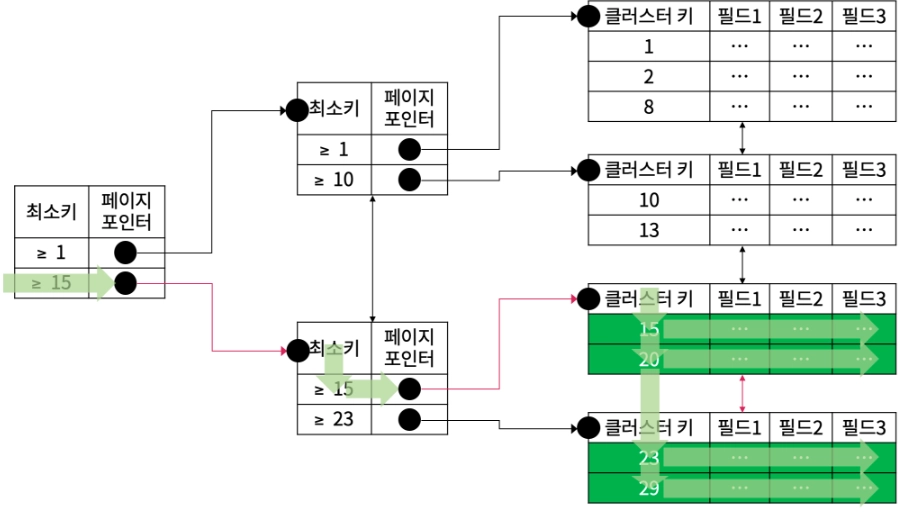
2. 기본키 인덱스와 실행 계획
참고: 클러스터 테이블이란?
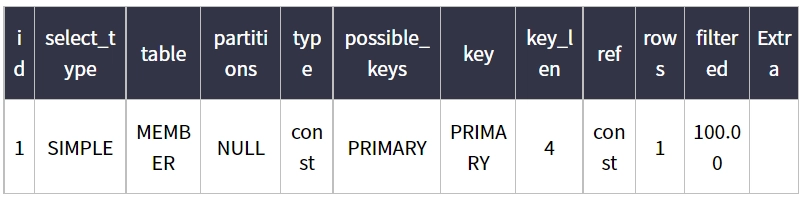
1. { Type : const } , { possible_keys : PRIMARY } , { key : PRIMARY } , { Extra : Using Index }
EXPLAIN SELECT M_ID FROM MEMBER WHERE M_ID = 15;
SQL
복사
•
기본키를 기준으로한 클러스터 인덱스가 존재하므로, M_ID만 가져오는 경우 레코드의 필드에 접근하지 않고 클러스터 키를 찾아 M_ID 칼럼의 값을 가져온다.
2. { Type : const } , { possible_keys : PRIMARY } , { key : PRIMARY } , { Extra : null }
SELECT * FROM MEMBER WHERE M_ID = 15;
SQL
복사
1번과 같이 M_ID값만 불러오는 것이 아니라 단일 행을 가져오는 것이므로 비슷한 루트로 진행되지만 이번엔 레코드 필드에 접근하여 값을 불러온다.
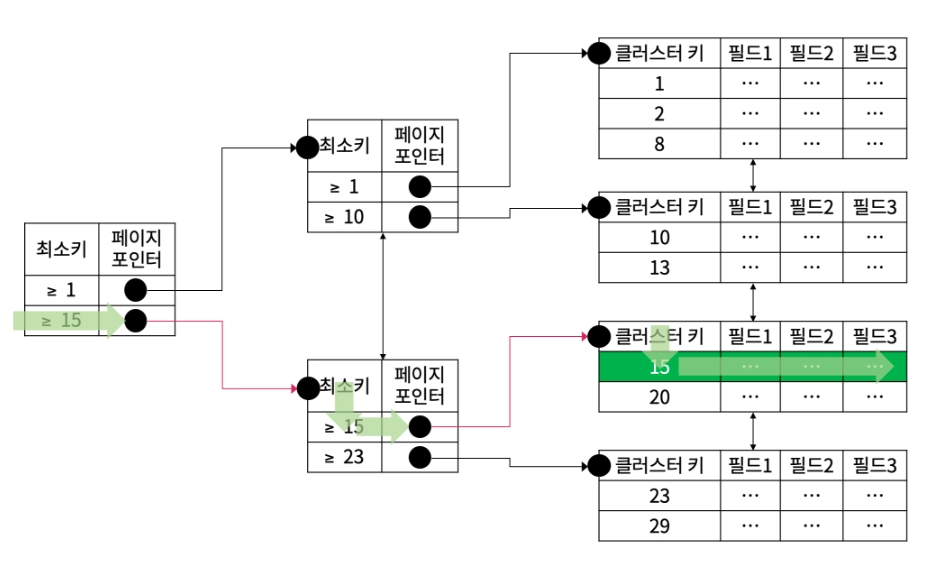
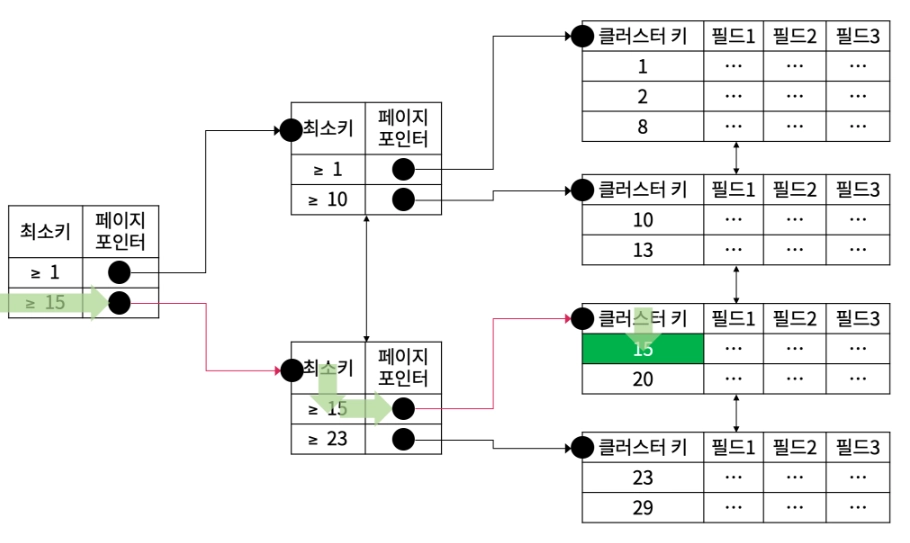
3. { Type : range } , { possible_keys : PRIMARY } , { key : PRIMARY } , { Extra : Using where; Using Index }
EXPLAIN SELECT M_ID FROM MEMBER WHERE M_ID >= 15;
SQL
복사
•
레인지 스캔 : 필드에 접근하지 않고 인덱스에 해당하는 부분만 접근하되 모든 인덱스가 아니라 특정 레코드부터 시작하여 범위적으로 인덱스를 스캔 하는 것
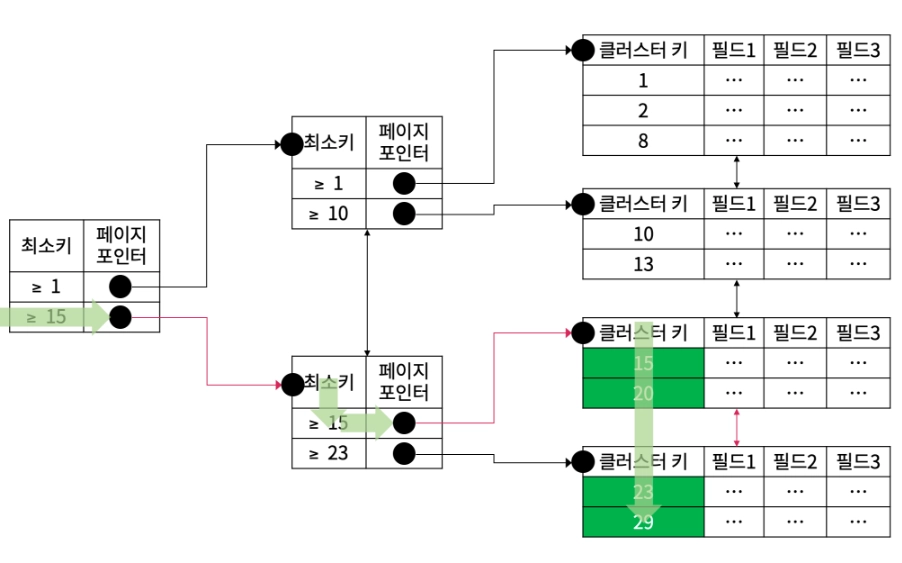
4. { Type : range } , { possible_keys : PRIMARY } , { key : PRIMARY } , { Extra : Using where }
EXPLAIN SELECT * FROM MEMBER WHERE M_ID >= 15;
SQL
복사
3번과 같이 M_ID값만 불러오는 것이 아니라 단일 행을 가져오는 것이므로 비슷한 루트로 진행되지만 이번엔 레코드 필드에까지 접근하여 값을 불러온다.
3. 유니크 인덱스와 실행계획
•
보조인덱스가 존재하는 테이블은 클러스트터 인덱스만 있는 테이블보다 좀 더 빠르게 원하는 행을 찾을 수도 있다. 이제 부터 그 예시를 살펴보도록 하자.
1. { Type : const } , { possible_keys : M_MEMBER_ID } , { key : M_MEMBER_ID } , { Extra : Using Index }
EXPLAIN SELECT M_MEMBER_ID FROM MEMBER WHERE M_MEMBER_ID = 'test7';
SQL
복사
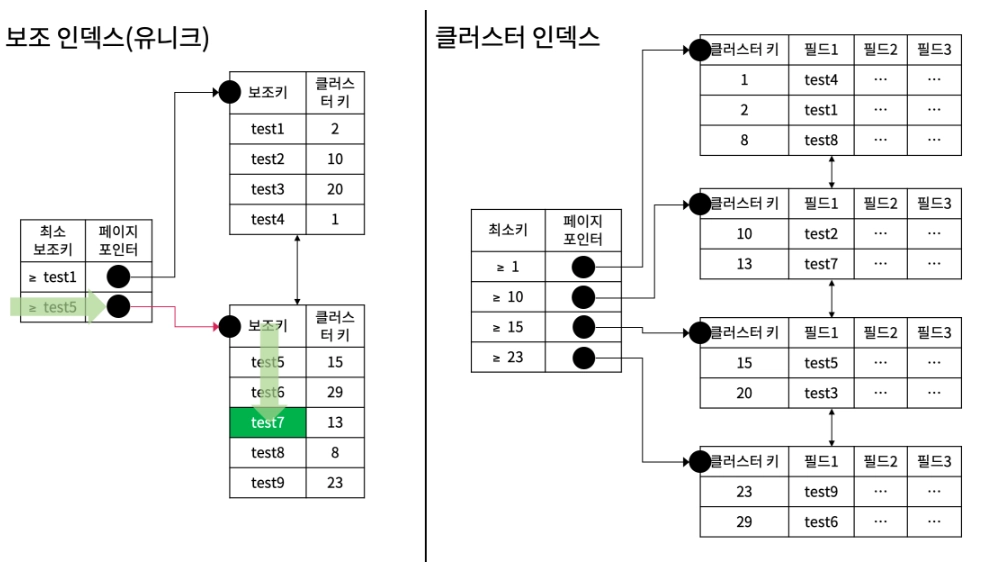
보조 인덱스만을 이용해서 탐색이 완료되며 클러스터 인덱스에 접근하지 않는다.
2. { Type : const } , { possible_keys : M_MEMBER_ID } , { key : M_MEMBER_ID } , { Extra : null }
EXPLAIN SELECT * FROM MEMBER WHERE M_MEMBER_ID = 'test7';
SQL
복사
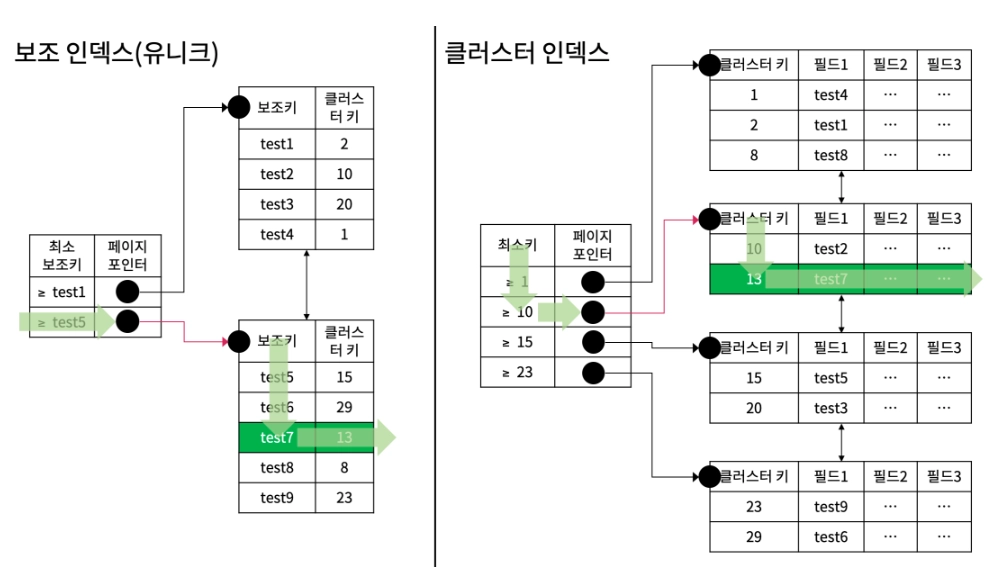
1과 달리, 인덱스에만 접근하는 것이 아닌 필드값을 불러오려면 필드값을 가지고 있는 클러스터 인덱스에 접근해야만 한다.
4. 칼럼 인덱스와 실행계획
•
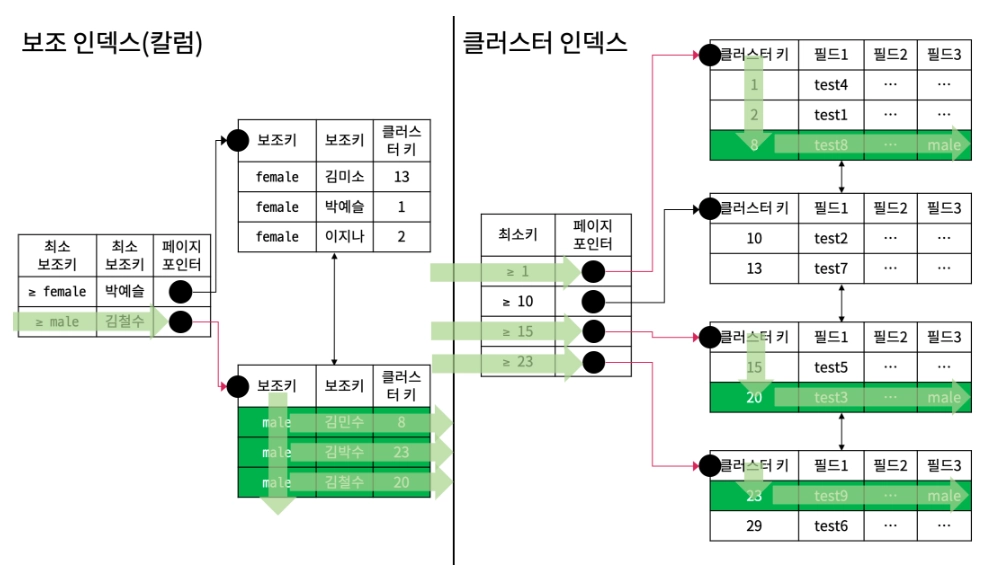
다중칼럼 인덱스는 보조키(칼럼)의 순서가 정렬의 중요한 기준이 된다.
ex) gender_name : gender기준으로 정렬, name은 gender 기준내에서 정렬
1. { Type : ref } , { possible_keys : gender_name } , { key : gender_name } , { Extra : Using Index }
EXPLAIN SELECT M_GENDER, M_NAME FROM MEMBER WHERE M_GENDER = 'male';
SQL
복사
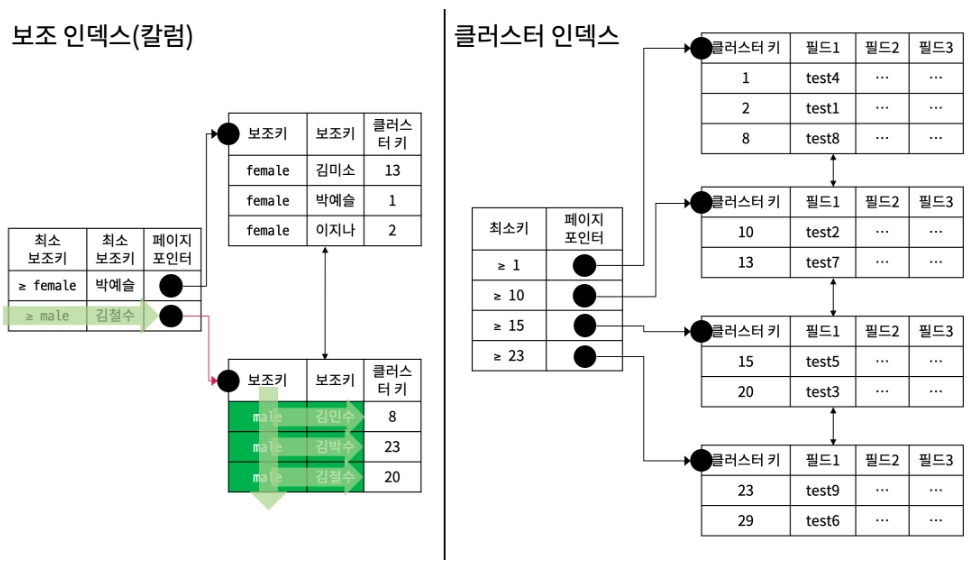
보조 인덱스를 이용하며 male 보조키를 가진 레코드를 탐색한다. M_gender와 M_name은 인덱스 내에 보조키로 존재하므로 클러스터 인덱스에 접근하지 않고, M_gender와 M_name 칼럼의 값을 가져온다.
2. { Type : ref } , { possible_keys : gender_name } , { key : gender_name } , { Extra : null }
EXPLAIN SELECT * FROM MEMBER WHERE M_GENDER = 'male';
SQL
복사
5. 인덱스를 이용한 최적화 질의가 적용이 안되는 경우_ 칼럼의 순서
•
인덱스 지정시 칼럼의 순서에 따라 동일한 질의도 인덱스를 이용할 수도 있고 이용하지 못할 수도 있다.
•
결론적으로 인덱스의 순서와 질의에 따라 인덱스를 효율적으로 이용할 수 있을지가 결정된다. 그러므로 인덱스를 설계할 때 질의를 예측해서 설계해야한다.
•
아래의 효율/비효율 예시들을 살펴보자.
효율X, 인덱스풀스캔의 예시
효율X, 풀스캔의 예시
효율 O
6. 인덱스로 지정되지 않은 칼럼
•
인덱스로 지정되지 않은 칼럼을 기준으로 조건에 맞는 행을 찾을 시, 테이블의 기본 구조인 클러스터 인덱스의 리프노드의 모든 필드를 전체 탐색하여 찾아야 한다.
풀스캔
7. 인덱스와 정렬
•
인덱스는 default로 오름차순 정렬되어 있고, 사용자가 인덱스를 생성 시 정렬 방향을 정할 수도 있다.
•
ASC - 오름차순 / DESC - 내림차순
ALTER TABLE MEMBER ADD INDEX `gender_name` (M_GENDER ASC, M_NAME DESC);
SQL
복사
